Releases: cloudposse/terraform-aws-eks-node-group
v3.1.1
🐛 Bug Fixes
Suppress EKS bootstrap when "after bootstrap" script is supplied @Nuru (#200)
## what- Suppress EKS-supplied bootstrap when
after bootstrapscript is supplied
why
- Fixes #195
references
- Supersedes and closes #198
🤖 Automatic Updates
Migrate new test account @osterman (#197)
## what - Update `.github/settings.yml` - Update `.github/chatops.yml` fileswhy
- Re-apply
.github/settings.ymlfrom org level to getterratestenvironment - Migrate to new
testaccount
References
- DEV-388 Automate clean up of test account in new organization
- DEV-387 Update terratest to work on a shared workflow instead of a dispatch action
- DEV-386 Update terratest to use new testing account with GitHub OIDC
Update .github/settings.yml @osterman (#196)
## what - Update `.github/settings.yml` - Drop `.github/auto-release.yml` fileswhy
- Re-apply
.github/settings.ymlfrom org level - Use organization level auto-release settings
references
- DEV-1242 Add protected tags with Repository Rulesets on GitHub
Contributors
Assets 2
v3.1.0
feat: Add missed tags @MaxymVlasov (#191)
## whatAdd tags to resources where they missed
🤖 Automatic Updates
Update .github/settings.yml @osterman (#190)
## what - Update `.github/settings.yml` - Drop `.github/auto-release.yml` fileswhy
- Re-apply
.github/settings.ymlfrom org level - Use organization level auto-release settings
references
- DEV-1242 Add protected tags with Repository Rulesets on GitHub
Bump the go_modules group in /test/src with 3 updates @dependabot (#189)
Bumps the go_modules group in /test/src with 3 updates: [github.com/hashicorp/go-getter](https://github.com/hashicorp/go-getter), [github.com/prometheus/client_golang](https://github.com/prometheus/client_golang) and [google.golang.org/grpc](https://github.com/grpc/grpc-go).Updates github.com/hashicorp/go-getter from 1.7.1 to 1.7.5
Release notes
Sourced from github.com/hashicorp/go-getter's releases.
v1.7.5
What's Changed
- Prevent Git Config Alteration on Git Update by
@dduzgun-securityin hashicorp/go-getter#497New Contributors
@dduzgun-securitymade their first contribution in hashicorp/go-getter#497Full Changelog: hashicorp/go-getter@v1.7.4...v1.7.5
v1.7.4
What's Changed
- Escape user-provided strings in
gitcommands hashicorp/go-getter#483- Fixed a bug in
.netrchandling if the file does not exist hashicorp/go-getter#433Full Changelog: hashicorp/go-getter@v1.7.3...v1.7.4
v1.7.3
What's Changed
- SEC-090: Automated trusted workflow pinning (2023-04-21) by
@hashicorp-tsccrin hashicorp/go-getter#432- SEC-090: Automated trusted workflow pinning (2023-09-11) by
@hashicorp-tsccrin hashicorp/go-getter#454- SEC-090: Automated trusted workflow pinning (2023-09-18) by
@hashicorp-tsccrin hashicorp/go-getter#458- don't change GIT_SSH_COMMAND when there is no sshKeyFile by
@jbardinin hashicorp/go-getter#459New Contributors
@hashicorp-tsccrmade their first contribution in hashicorp/go-getter#432Full Changelog: hashicorp/go-getter@v1.7.2...v1.7.3
v1.7.2
What's Changed
- Don't override
GIT_SSH_COMMANDwhen not needed by@nl-brett-stimehashicorp/go-getter#300Full Changelog: hashicorp/go-getter@v1.7.1...v1.7.2
Commits
5a63fd9Merge pull request #497 from hashicorp/fix-git-update5b7ec5ffetch tags on update and fix tests9906874recreate git config during update to prevent config alteration268c11cescape user provide string to git (#483)975961fMerge pull request #433 from adrian-bl/netrc-fix0298a22Merge pull request #459 from hashicorp/jbardin/setup-git-envc70d9c9don't change GIT_SSH_COMMAND if there's no keyfile3d5770fMerge pull request #458 from hashicorp/tsccr-auto-pinning/trusted/2023-09-180688979Result of tsccr-helper -log-level=info -pin-all-workflows .e66f244Merge pull request #454 from hashicorp/tsccr-auto-pinning/trusted/2023-09-11- Additional commits viewable in compare view
Updates github.com/prometheus/client_golang from 1.11.0 to 1.11.1
Release notes
Sourced from github.com/prometheus/client_golang's releases.
1.11.1 / 2022-02-15
- [SECURITY FIX] promhttp: Check validity of method and code label values prometheus/client_golang#987 (Addressed
CVE-2022-21698)What's Changed
- promhttp: Check validity of method and code label values by
@bwplotkaand@kakkoyunin prometheus/client_golang#987Full Changelog: prometheus/client_golang@v1.11.0...v1.11.1
Changelog
Sourced from github.com/prometheus/client_golang's changelog.
Unreleased
1.19.0 / 2023-02-27
The module
prometheus/common v0.48.0introduced an incompatibility when used together with client_golang (See prometheus/client_golang#1448 for more details). If your project uses client_golang and you want to useprometheus/common v0.48.0or higher, please update client_golang to v1.19.0.
- [CHANGE] Minimum required go version is now 1.20 (we also test client_golang against new 1.22 version). #1445 #1449
- [FEATURE] collectors: Add version collector. #1422 #1427
1.18.0 / 2023-12-22
- [FEATURE] promlint: Allow creation of custom metric validations. #1311
- [FEATURE] Go programs using client_golang can be built in wasip1 OS. #1350
- [BUGFIX] histograms: Add timer to reset ASAP after bucket limiting has happened. #1367
- [BUGFIX] testutil: Fix comparison of metrics with empty Help strings. #1378
- [E...
Contributors
Assets 2
v3.0.1
v3.0.0
New Features, Breaking Changes
tl;dr Upgrading to this version will likely cause your node group to be replaced, but otherwise should not have much impact for most users.
The major new feature in this release is support for Amazon Linux 2023 (AL2023). EKS support for AL2023 is still evolving, and this module will evolve along with that. Some detailed configuration options (e.g. KubeletConfiguration JSON) are not yet supported, but the basic features are there.
The other big improvements are in immediately applying changes and in selecting AMIs, as explained below.
Along with that, we have dropped some outdated support and changed the eks_node_group_resources output, resulting in minor breaking changes that we expect do not affect many users.
Create Before Destroy is Now the Default
Previously, when changes forced the creation of a new node group, the default behavior for this module was to delete the existing node group and then create a replacement. This is the default for Terraform, motivated in part by the fact that the node group's name must be unique, so you cannot create the new node group with the same name as the old one while the old one still exists.
With version 2 of this module, we recommended setting create_before_destroy to true to enable this module to create a new node group (with a partially randomized name) before deleting the old one, allowing the new one to take over for the old one. For backward compatibility, and because changing this setting always results in creating a new node group, the default setting was set to false.
With this release, the default setting of create_before_destroy is now true, meaning that if left unset, any changes requiring a new node group will cause a new node group to be created first, and then the existing node group to be deleted. If you have large node groups or small quotas, this can fail due to having the 2 node groups running at the same time.
Random name length now configurable
In order to support "create before destroy" behavior, this module uses the random_pet
resource to generate a unique pet name for the node group, since the node group name
must be unique, meaning the new node group must have a different name than not only the old one, but also all other node groups you have. Previously, the "random" pet name was 1 of 452 possible names, which may not be enough to avoid collisions when using a large number of node groups.
To address this, this release introduces a new variable, random_pet_length, that controls the number of pet names concatenated to form the random part of the name. The default remains 1, but now you can increase it if needed. Note that changing this value will always cause the node group name to change and therefore the node group to be replaced.
Immediately Apply Launch Template Changes
This module always uses a launch template for the node group. If one is not supplied, it will be created.
In many cases, changes to the launch template are not immediately applied by EKS. Instead, they only apply to Nodes launched after the template is changed. Depending on other factors, this may mean weeks or months pass before the changes are actually applied.
This release introduces a new variable, immediately_apply_lt_changes, to address this. When set to true, any changes to the launch template will cause the node group to be replaced, ensuring that all the changes are made immediately. (Note: you may want to adjust the node_group_terraform_timeouts if you have big node groups.)
The default value for immediately_apply_lt_changes is whatever the value of create_before_destroy is.
Changes in AMI selection
Previously, if the created launch template needed to supply an AMI ID (which is only the case if you supplied kubelet or bootstrap options), unless you specified a specific AMI ID, this module picked the "newest" AMI that met the selection criteria, which in turn was based on the AMI Name. The problem with that was that the "newest" might not be the latest Kubernetes version. It might be an older version that was patched more recently, or simply finished building a little later than the latest version.
Now that AWS explicitly publishes the AMI ID corresponding to the latest (or, more accurately, "recommended") version of their AMIs via SSM Public Parameters, the module uses that instead. This is more reliable and should eliminate the version regression issues that occasionally happened before.
The ami_release_version input has been updated
The ami_release_version input has been updated. It is the value that you can supply to aws_eks_node_group to track a specific patch version of Kubernetes. The previous validation for this variable was incorrect.
- For Amazon Linux, it is the "Release version" from Amazon AMI Releases
- For Bottlerocket, it is the release tag from Bottlerocket Releases without the "v" prefix.
- For Windows, it is "AMI version" from AWS docs.
Note that unlike AMI names, release versions never include the "v" prefix.
Examples of AMI release versions based on OS:
- Amazon Linux 2 or 2023: 1.29.3-20240531
- Bottlerocket: 1.18.0 or 1.18.0-7452c37e # note commit hash prefix is 8 characters, not GitHub's default 7
- Windows: 1.29-2024.04.09
Customization via userdata
Unsupported userdata now throws an error
Node configuration via userdata is different for each OS. This module has 4 inputs related to Node configuration that end up using userdata:
before_cluster_joining_userdatakubelet_additional_optionsbootstrap_additional_optionsafter_cluster_joining_userdata
but they do not all work for all OSes, and none work for Botterocket. Previously, they were silently ignored in some cases. Now they throw an error when set for an unsupported OS.
Note that for all OSes, you can bypass all these inputs and supply your own fully-formed, base64 encoded userdata via userdata_override_base64, and this module will pass it along unmodified.
Multiple lines supported in userdata scripts
All the userdata inputs take lists, because they are optional inputs. Previously, lists were limited to single elements. Now the list can be any length, and the elements will be combined.
Kubernetes Version No Longer Inferred from AMI
Previously, if you specified an AMI ID, the Kubernetes version would be deduced from the AMI ID name. That is not sustainable as new OSes are launched, so the module no longer tries to do that. If you do not supply the Kubernetes version, the EKS cluster's Kubernetes version will be used.
Output eks_node_group_resources changed
The aws_eks_node_group.resources attribute is a "list of objects containing information about underlying resources." Previously, this was output via eks_node_group_resources as a list of lists, due to a quirk of Terraform. It is now output as a list of resources, in order to align with the other outputs.
Special Support for Kubernetes Cluster Autoscaler removed
This module used to takes some steps (mostly labeling) to try to help the Kubernetes Cluster Autoscaler. As the Cluster Autoscaler and EKS native support for it evolved, the steps taken became either redundant or ineffective, so they have been dropped.
cluster_autoscaler_enabledhas been deprecated. If you set it, you will get a warning in the output, but otherwise it has no effect.
AWS Provider v5.8 or later now required
Previously, this module worked with AWS Provider v4, but no longer. Now v5.8 or later is required.
Special Thanks
This PR builds on the work of @Darsh8790 (#178 and #180) and @QuentinBtd (#182 and #185). Thank you to both for your contributions.
🚀 Enhancements
Consolidate updates to test framework @Nuru (#177)
what
- Update
gok8s client and api packages to v0.29.4 - Update
godepenendcies
why
- Track update to Kubernetes cluster version in #173
- Resolve security alerts
references
feat: migrates example on eks-cluster-aws-4.x @gberenice (#173)
what
- Upgrade the example to use eks-cluster v4.x.x, where any dependencies on the Kubernetes provider were removed.
why
- This eliminates the Terraform test error caused by the kubernetes provider issue. As a consequence, this unlocks merging the PRs. Example of the error:
Error: Received unexpected error:
FatalError{Underlying: error while running command: exit status 1; ╷
│ Error: Value Conversion Error
│
│ with module.eks_cluster.provider["registry.terraform.io/hashicorp/kubernetes"],
│ on .terraform/modules/eks_cluster/auth.tf line 96, in provider "kubernetes":
│ 96: provider "kubernetes" {
references
- Migration guide
- Latest example for eks-cluster
- [Initial discussion in the
contributorsSlac...
Contributors
Assets 2
v2.12.0
Add `force_update_version` and `replace_node_group_on_version_update` variables @aknysh (#151)
what
- Add
force_update_versionandreplace_node_group_on_version_updatevariables
why
-
force_update_versionallows forcing version update if existing pods are unable to be drained due to a pod disruption budget issue. Default isfalsefor backwards compatibility -
If the variable
replace_node_group_on_version_updateis set totrueand the EKS cluster is updated to a new Kubernetes version, the Node Groups will be replaced instead of updated in-place. This is useful when updating very old EKS clusters to a new Kubernetes version where some old releases prevent nodes from being drained (due to PodDisruptionBudget or taint/toleration issues), but replacing the Node Groups works without forcing the pods to leave the old nodes by using theforce_update_versionvariable. This is related, for example, toistio. Default isfalsefor backwards compatibility
references
Contributors
Assets 2
v2.11.0
Better block device support @Nuru (#150)
Notable Changes
- With this PR/release, the default type of block device changes from
gp2togp3. If you were relying on the default, this will cause your node group to change, but it should be without interruption. - We no longer automatically apply a custom taint to Window nodes. Pods should select (or not) Windows nodes via the
kubernetes.io/ostag. If that is not sufficient, you are free to add your own "NO_EXECUTE" taint viakubernetes_taints
what
- Better support for block device mapping
- Update dependency
terraform-aws-security-groupto current v2.2.0 - Revert portions of #139
why
- Take advantage of
optional()to allow the block device mapping input to be fully specified, with defaults, rather than the previouslist(any), which had no type checking and did not advertise which features were or were not supported - Closes #134
- Bad practices that were not caught in time
add core_count and threads_per_core options to launch templates @Dmitry1987 (#149)
what
added core_count and threads_per_core options in order to run instances with no hyperthreading, for applications that need maximize single core performance (in some cases it's required).
why
the config option is available in the module but was not available in variables
references
Support AWS Provider V5 @max-lobur (#147)
what
Support AWS Provider V5
Linter fixes
why
Maintenance
references
https://github.com/hashicorp/terraform-provider-aws/releases/tag/v5.0.0
Do not sort instance types @xeivieni (#142)
what
Remove sorting on instance type list in the node group definition
why
Because the order of the list is used to define priorities on the type of instance to use.
references
Managed node groups use the order of instance types passed in the API to determine which instance type to use first when fulfilling On-Demand capacity. For example, you might specify three instance types in the following order: c5.large, c4.large, and c3.large. When your On-Demand Instances are launched, the managed node group fulfills On-Demand capacity by starting with c5.large, then c4.large, and then c3.large
Sync github @max-lobur (#145)
Rebuild github dir from the template
🤖 Automatic Updates
Update README.md and docs @cloudpossebot (#148)
what
This is an auto-generated PR that updates the README.md and docs
why
To have most recent changes of README.md and doc from origin templates
Contributors
Assets 2
v2.10.0
- No changes
v2.9.1
Use cloudposse/template for arm support @nitrocode (#129)
what
- Use cloudposse/template for arm support
why
- The new cloudposse/template provider has a darwin arm binary for M1 laptops
references
🚀 Enhancements
fix: variable description for var.bootstrap_additional_options @venkatamutyala (#144)
what
- Fixing variable description as it references another variable that doesn't exist.
why
Should save someone time in the future when they try and find the variable as mentioned in the description.
Contributors
Assets 2
v2.9.0
Groundwork new workflows @max-lobur (#143)
Fix lint/format before workflows rollout
Contributors
Assets 2
v2.8.0
Windows node support @ChrisMcKee (#139)
what
- Adds support for 2019/2022 (windows lts) ami-types as per the aws sdk docs
- Docs to support usage and link to ref docs https://docs.aws.amazon.com/eks/latest/userguide/windows-support.html
why
- Windows EKS Managed node support aws/containers-roadmap#584
references
- https://docs.aws.amazon.com/eks/latest/userguide/windows-support.html
- https://docs.aws.amazon.com/eks/latest/userguide/eks-ami-versions-windows.html
Tested
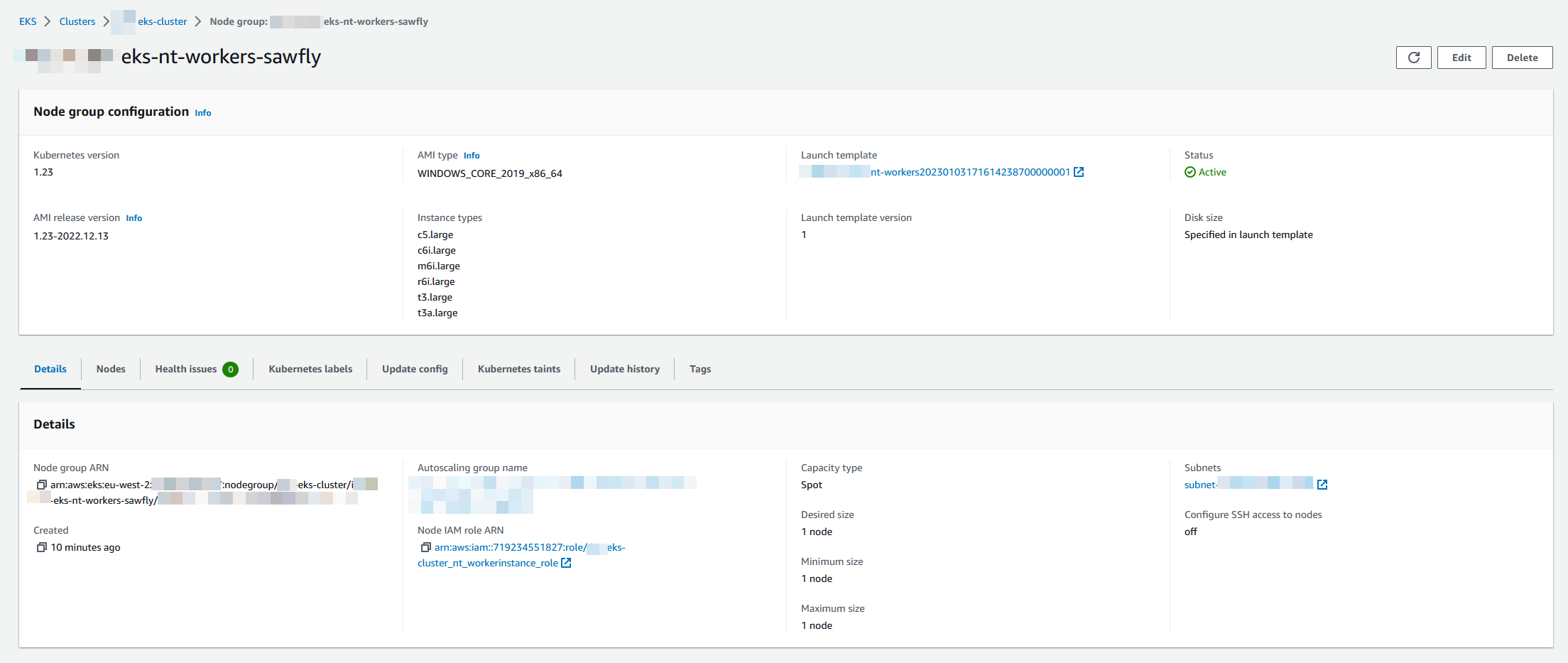



module "eks_windows_node_group" {
# source = "cloudposse/eks-node-group/aws"
# version = "2.6.1"
source = "github.com/ChrisMcKee/terraform-aws-eks-node-group"
instance_types = ["t3.large", "t3a.large", "c5.large", "c6i.large", "m6i.large", "r6i.large"]
subnet_ids = [data.terraform_remote_state.network.outputs.private_subnets[1]]
min_size = 1
max_size = 1
desired_size = 1
cluster_name = module.eks_cluster.eks_cluster_id
kubernetes_version = var.kubernetes_version == null || var.kubernetes_version == "" ? [] : [var.kubernetes_version]
kubernetes_labels = var.labels
ami_type = "WINDOWS_CORE_2019_x86_64"
update_config = [{ max_unavailable = 1 }]
capacity_type = "SPOT"
kubernetes_taints = [{
key = "OS"
value = "Windows"
effect = "NO_SCHEDULE"
}]
node_role_arn = [aws_iam_role.worker_role_nt.arn]
node_role_cni_policy_enabled = false #We use the Service Account as per best practice
associated_security_group_ids = [data.terraform_remote_state.network.outputs.ops_ssh, aws_security_group.workers.id]
# Enable the Kubernetes cluster auto-scaler to find the auto-scaling group
cluster_autoscaler_enabled = true
context = module.windowslabel.context
# Ensure the cluster is fully created before trying to add the node group
module_depends_on = [module.eks_cluster.kubernetes_config_map_id]
# Ensure ordering of resource creation to eliminate the race conditions when applying the Kubernetes Auth ConfigMap.
# Do not create Node Group before the EKS cluster is created and the `aws-auth` Kubernetes ConfigMap is applied.
depends_on = [module.eks_cluster, module.eks_cluster.kubernetes_config_map_id]
create_before_destroy = true
node_role_policy_arns = ["arn:aws:iam::aws:policy/AmazonSSMManagedInstanceCore"]
block_device_mappings = [
{
"delete_on_termination" : true,
"device_name" : "/dev/xvda",
"encrypted" : true,
"volume_size" : 80,
"volume_type" : "gp3"
}
]
node_group_terraform_timeouts = [{
create = "40m"
update = null
delete = "20m"
}]
#Valid types are "instance", "volume", "elastic-gpu", "spot-instances-request", "network-interface".
resources_to_tag = ["instance", "volume", "spot-instances-request", "network-interface"]
}