Implements the CombSort algorithm #54
Conversation
Codecov Report
@@ Coverage Diff @@
## master #54 +/- ##
==========================================
+ Coverage 96.40% 96.51% +0.10%
==========================================
Files 1 1
Lines 334 344 +10
==========================================
+ Hits 322 332 +10
Misses 12 12
📣 We’re building smart automated test selection to slash your CI/CD build times. Learn more |
|
Thanks. Contrary to Base, I don't think systematic benchmarks are needed to include a new algorithm in this package. The point of SortingAlgorithms.jl is to provide a variety of algorithms. However, it should give correct results or throw an error for unsupported values or types. It's surprising that tests pass with It would be good to add tests for other types BTW (strings, custom type, |
|
Thank you, looking forward to contributing this and perhaps other algorithms later. I was perhaps a bit fast to judge, the implementation actually does seem to work: My confusion is because I was testing with direct calls to the 6-parameters method, and I guess I picked the wrong choice for the ordering parameter. I suppose I just don't understand exactly how that works. What happens is that if I call it with My uncertainty was later reinforced because it seems the test checks for "issorted" instead of comparing the output to a vector sorted by another method, and if the output was all It all seems to be fine, though, I just don't understand the mechanics of the |
|
Sorry for the delay. I don't think you should be concerned with |
|
Can somebody help me here? What are we missing to go ahead? |
|
Thanks for the review, I believe I have covered everything. |
There was a problem hiding this comment.
I've been doing a bit of benchmarking, and this looks really good! It seems to be faster than any algorithm I know of for unstable sorting of primitives in default order of length about 10–1500. That's a very particular domain, but also a fairly common use case and a case where Julia currently struggles.
src/SortingAlgorithms.jl
Outdated
| - H. Inoue, T. Moriyama, H. Komatsu and T. Nakatani, "AA-Sort: A New Parallel Sorting Algorithm for Multi-Core SIMD Processors," 16th International Conference on Parallel Architecture and Compilation Techniques (PACT 2007), 2007, pp. 189-198, doi: 10.1109/PACT.2007.4336211. | ||
| - Werneck, N. L., (2020). ChipSort: a SIMD and cache-aware sorting module. JuliaCon Proceedings, 1(1), 12, https://doi.org/10.21105/jcon.00012 |
There was a problem hiding this comment.
Both of these works describe different and much larger sorting algorithms. CombSort (Albeit with a bubble finish) was introduced in a one-pager from 1980: Dobosiewicz, Wlodzimierz, "An efficient variation of bubble sort", Information Processing Letters, 11(1), 1980, pp. 5-6, https://doi.org/10.1016/0020-0190(80)90022-8.
There was a problem hiding this comment.
We can add further references if you like, but please add them as suggestions in this case. It feels enough to me.
This implementation is the "default" method presented in ChipSort.jl, and the inspiration came mostly from AA-Sort. I'm not sure earlier papers discuss vectorization, and the early history of all these algorithms gets a little murky. I recommend following the citations in Section 2.4 of the ChipSort paper, which includes Knuth, and also this wiki which has a good recap. They cite Dobosiewicz there (and Knuth himself also did in a later edition of his book). https://code.google.com/archive/p/combsortcs2p-and-other-sorting-algorithms/wikis/CombSort.wiki
The algorithm in AA-Sort Figure 2 actually finishes with bubble sort as well. That's why I point out finishing with insertion might be the small contribution from the ChipSort paper. Although it's a pretty conventional idea, as explained in sec 2.4. What's still a mystery is whether this comb+insertion approach might be guaranteed to have n.log(n) complexity.
There was a problem hiding this comment.
While I view Wlodzimierz's piece as a concise exposition of CombSort, I view the AA-Sort paper as a longer analysis of a set of modifications to CombSort. Does this PR implement the modifications the AA-Sort paper describes?
The second reference seems more appropriate, but IIUC the only part of that paper that describes this algorithm is the first half of section 2.4.
There was a problem hiding this comment.
If you would like a more specific reference, it may not exist. This PR is a result of finding out, amidst the other investigations in ChipSort, that this simple algorithm can be well vectorized and offers a great performance.
Indeed, very little from the AA-sort paper is here. It was just the original inspiration, and I feel I can't just cite myself, although I wouldn't object to.
There was a problem hiding this comment.
I think it would be reasonable to just cite yourself or to cite yourself first followed by AA-Sort
Cool! Are you talking about any cases where Radix cannot be applied? I'm not sure I've ever seen a case where Radix does not win, not even very specific examples. That's one unfortunate omission in the ChipSort paper, I didn't get to benchmark against Radix. Which I also understand is now finally going to be offered in One interesting technique for small inputs is sorting networks. ChipSort.jl has it, and I believe there are other packages offering it as well. |
What radix sort were you comparing to? The one in Base is slower than CombSort for 700 julia> @btime sort!(x; alg=CombSort) setup=(x=rand(Int, 700)) evals=1;
10.110 μs (0 allocations: 0 bytes)
julia> @btime sort!(x) setup=(x=rand(Int, 700)) evals=1; # Adaptive sort dispatching to radix sort
12.163 μs (3 allocations: 7.84 KiB)
julia> versioninfo()
Julia Version 1.9.0-DEV.1035
Commit 52f5dfe3e1* (2022-07-20 20:15 UTC)
Platform Info:
OS: macOS (x86_64-apple-darwin21.3.0)
CPU: 4 × Intel(R) Core(TM) i5-8210Y CPU @ 1.60GHz
WORD_SIZE: 64
LIBM: libopenlibm
LLVM: libLLVM-14.0.5 (ORCJIT, skylake)
Threads: 1 on 2 virtual cores
Environment:
LD_LIBRARY_PATH = /usr/local/lib
JULIA_PKG_PRECOMPILE_AUTO = 0 |
|
Interesting, I'm not familiar yet with what's been added to base. I think there's a package that specifically implements radix sort, and that's what I've tried in the past. Maybe it uses a few extra tricks. One of my arguments for having comb sort in base was that implementing radix is not as easy, so I'm curious to find out if the implementation there is outperformed. I've never actually understood how radix can make use of any ILP, what's simple to understand with comb. It might be that some small detail is missing in base to enable vectorization. Or otherwise it might be just a case of tuning eg when to switch to insertion sort. I'll definitely make some experiments later now that you showed me that! |
|
We should mention asymptotic runtime (c.f. JuliaLang/julia#46679 (comment)) |
|
I think this is very close to ready. All it needs are a couple of documentation changes and a rebase/merge onto the latest master to make sure tests pass on nightly. It's a neat algorithm that I'd like to see merged! |
|
Sure thing, I hope to do it later today or tomorrow
…On Sun, 2 Oct 2022, 05:15 Lilith Orion Hafner, ***@***.***> wrote:
I think this is very close to ready. All it needs are a couple of
documentation changes and a rebase/merge onto the latest master to make
sure tests pass on nightly.
—
Reply to this email directly, view it on GitHub
<#54 (comment)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AABHKEQWFAMVFF7WOP2EFVTWBD43NANCNFSM5O2OTAQA>
.
You are receiving this because you authored the thread.Message ID:
***@***.***>
|
Co-authored-by: Milan Bouchet-Valat <nalimilan@club.fr>
Co-authored-by: Milan Bouchet-Valat <nalimilan@club.fr>
Co-authored-by: Milan Bouchet-Valat <nalimilan@club.fr>
Co-authored-by: Lilith Orion Hafner <lilithhafner@gmail.com>
Co-authored-by: Lilith Orion Hafner <lilithhafner@gmail.com>
|
@LilithHafner I've changed the docstring and rebased, hope it's all fine now |
src/SortingAlgorithms.jl
Outdated
| - *in-place* in memory. | ||
| - *parallelizable* suitable for vectorization with SIMD instructions | ||
| because it performs many independent comparisons. | ||
| - *complexity* worst-case only proven to be better than quadratic, but not `n*log(n)`. |
There was a problem hiding this comment.
This algorithm has quadratic worst-case runtime.
julia> @time sort!(4^7*repeat(1:30, 4^7));
0.027213 seconds (8 allocations: 11.258 MiB)
julia> @time sort!(4^7*repeat(1:30, 4^7); alg=CombSort);
4.866824 seconds (4 allocations: 7.500 MiB)Proof
Take an arbitrary k, let m = 4k, and let n = m*4^7. Consider the first 7 intervals for an input of length n: [n*(3/4)^i for i in 1:7] == [m*4^7*(3/4)^i for i in 1:7] == [m*4^(7-i)*3^i for i in 1:7]. Notice that each interval is divisible by m.
Now, construct a pathological input v = repeat(1:m, 4^7). This input has the property v[i] == v[i+*jm] for any intergers i and j which yield inbounds indices. Consequently, the first 7 passes cannot alter v at all.
Informal interlude: There are still a lot of low numbers near the end of the list, and the remaining passes will have a hard time moving them to the beginning because their intervals are fairly small.
Consider the elements 1:k that fall in the final quarter of v. There are k*4^7/4 = n/16 such elements. Each of them must end up in the first quarter of the list once sorted, so they must each travel a total of at least n/2 slots (in reality they must each travel more than this, but all I claim is a lower bound).
To recap, we have established n/16 elements that must travel at least n/2 slots, and that they do not travel at all in the first 7 passes. The remaining comb passes have intervals no greater than [n*(3/4)^i for i in 8:inf]. The furthest an elemental can move toward the start of the vector in a single pass is the interval size of that pass, so the furthest an element can move toward the start of the vector in all remaining passes combined is sum([n*(3/4)^i for i in 8:inf]) = n*(3/4)^8 / (1 - 3/4) = 4n*(3/4)^8 < 0.401n. Thus, after all the comb passes are compete, we will still have n/16 elements that have to move at least 0.099n slots toward the start of the vector. Insertion sort, which can only move one swap at a time will require 0.099n*n/4 > .024n^2 swaps to accomplish this. Therefore, the worst case runtime of this algorithm is Ω(n^2).
It is structurally impossible for this algorithm to take more than O(n^2) time, so we can conclude Θ(n^2) is a tight asymptotic bound on the worst case runtime of this implementation of combsort. (A similar analysis holds for any geometric interval distribution).
We can verify the math in this proof empirically:
code
function comb!(v)
lo, hi = extrema(eachindex(v))
interval = (3 * (hi-lo+1)) >> 2
while interval > 1
for j in lo:hi-interval
a, b = v[j], v[j+interval]
v[j], v[j+interval] = b < a ? (b, a) : (a, b)
end
interval = (3 * interval) >> 2
end
v
end
function count_insertion_sort!(v)
count = 0
lo, hi = extrema(eachindex(v))
for i = lo+1:hi
j = i
x = v[i]
while j > lo && x < v[j-1]
count += 1
v[j] = v[j-1]
j -= 1
end
v[j] = x
end
count
end
K = 1:6
M = 4 .* K
N = M .* 4^7
swaps = [count_insertion_sort!(comb!(repeat(1:m, 4^7))) for m in M]
using Plots
plot(N, swaps, label="actual swaps", xlabel="n", ylabel="swaps", legend=:topleft)
plot!(N, .024N.^2, label="theoretical minimum")Results
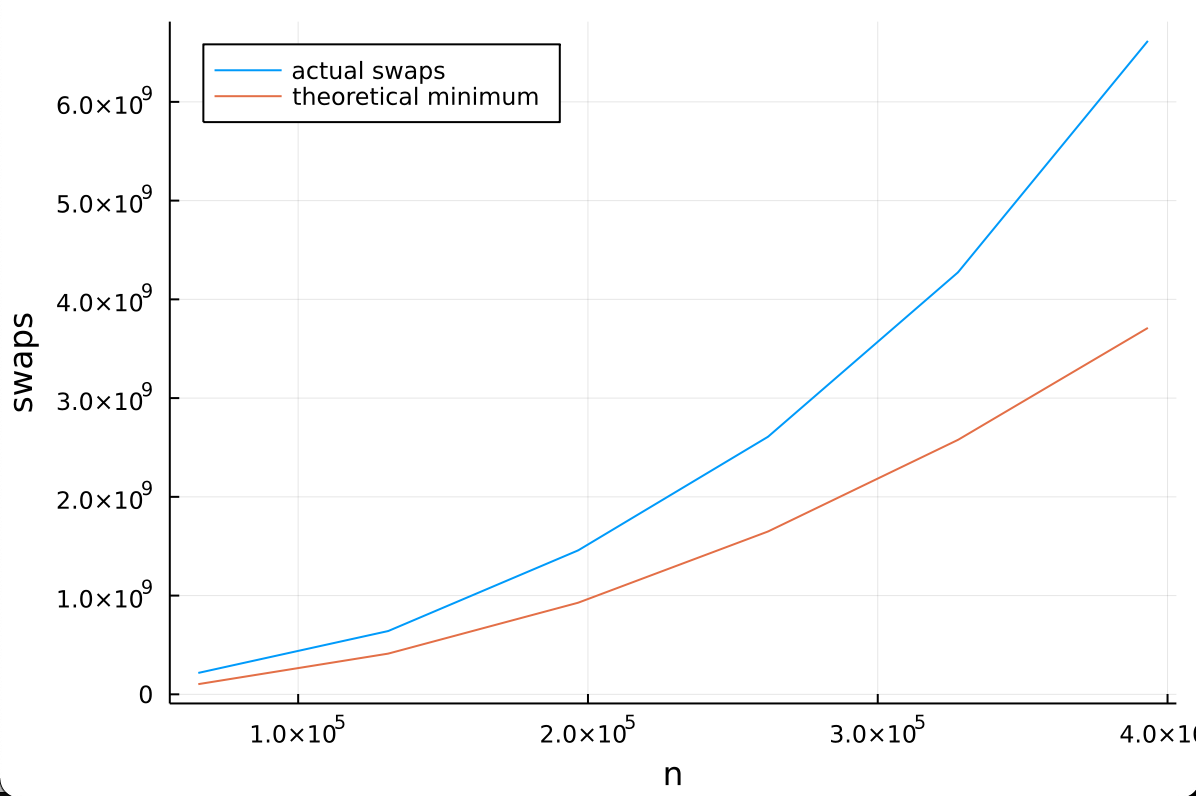
The proof conveniently provides us with a pathological input to test. So, even more empirically, we can simply measure runtime.
Code
# multiply by a large number ot avoid dispatch to counting sort
make_vector(m) = 4^7*repeat(1:m, 4^7)
x = 1:20
n = 4^7*x
comb = [(x = make_vector(m); @elapsed(sort!(x; alg=CombSort))) for m in x]
default = [(x = make_vector(m); @elapsed(sort!(x ))) for m in x]
theory = .024n.^2 / 1.6e9 # 1.6 ghz clock speed
plot(n, comb, label="comb sort", xlabel="n", ylabel="time (s)", legend=:topleft)
plot!(n, default, label="default sort")
plot!(n, theory, label="theoretical minimum")Results

|
I was just quoting the result from the third reference, my (shallow)
understanding is that they've proven a slightly better worst case than n2,
but it probably relies on some special way of reducing the intervals or
something like that...
…On Wed, 5 Oct 2022, 13:27 Lilith Orion Hafner, ***@***.***> wrote:
***@***.**** commented on this pull request.
------------------------------
In src/SortingAlgorithms.jl
<#54 (comment)>
:
> + CombSort
+
+Indicates that a sorting function should use the comb sort
+algorithm. Comb sort traverses the collection multiple times
+ordering pairs of elements with a given interval between them.
+The interval decreases exponentially until it becomes 1, then
+it switches to insertion sort on the whole input.
+
+Characteristics:
+ - *not stable* does not preserve the ordering of elements which
+ compare equal (e.g. "a" and "A" in a sort of letters which
+ ignores case).
+ - *in-place* in memory.
+ - *parallelizable* suitable for vectorization with SIMD instructions
+ because it performs many independent comparisons.
+ - *complexity* worst-case only proven to be better than quadratic, but not `n*log(n)`.
This algorithm has quadratic worst-case runtime.
julia> @time sort!(4^7*repeat(1:30, 4^7));
0.027213 seconds (8 allocations: 11.258 MiB)
julia> @time sort!(4^7*repeat(1:30, 4^7); alg=CombSort);
4.866824 seconds (4 allocations: 7.500 MiB)
------------------------------
Proof
Take an arbitrary k, let m = 4k, and let n = m*4^7. Consider the first 7
intervals for an input of length n: [n*(3/4)^i for i in 1:7] ==
[m*4^7*(3/4)^i for i in 1:7] == [m*4^(7-i)*3^i for i in 1:7]. Notice that
each interval is divisible by m.
Now, construct a pathological input v = repeat(1:m, 4^7). This input has
the property v[i] == v[i+*jm] for any intergers i and j which yield
inbounds indices. Consequently, the first 7 passes cannot alter v at all.
*Informal interlude: There are still a lot of low numbers near the end of
the list, and the remaining passes will have a hard time moving them to the
beginning because their intervals are fairly small.*
Consider the elements 1:k that fall in the final quarter of v. There are k*4^7/4
= n/16 such elements. Each of them must end up in the first quarter of
the list once sorted, so they must each travel a total of at least n/2
slots (in reality they must each travel more than this, but all I claim is
a lower bound).
To recap, we have established n/16 elements that must travel at least n/2
slots, and that they do not travel at all in the first 7 passes. The
remaining comb passes have intervals no greater than [n*(3/4)^i for i in
8:inf]. The furthest an elemental can move toward the start of the vector
in a single pass is the interval size of that pass, so the furthest an
element can move toward the start of the vector in all remaining passes
combined is sum([n*(3/4)^i for i in 8:inf]) = n*(3/4)^8 / (1 - 3/4) =
4n*(3/4)^8 < 0.401n. Thus, after all the comb passes are compete, we will
still have n/16 elements that have to move at least 0.099n slots toward
the start of the vector. Insertion sort, which can only move one swap at a
time will require 0.099n*n/4 > .024n^2 swaps to accomplish this.
Therefore, the worst case runtime of this algorithm is Ω(n^2).
It is structurally impossible for this algorithm to take more than O(n^2)
time, so we can conclude Θ(n^2) is a tight asymptotic bound on the worst
case runtime of this implementation of combsort. (A similar analysis holds
for any geometric interval distribution).
------------------------------
We can verify the math in this proof empirically:
code
function comb!(v)
lo, hi = extrema(eachindex(v))
interval = (3 * (hi-lo+1)) >> 2
while interval > 1
for j in lo:hi-interval
a, b = v[j], v[j+interval]
v[j], v[j+interval] = b < a ? (b, a) : (a, b)
end
interval = (3 * interval) >> 2
end
v
end
function count_insertion_sort!(v)
count = 0
lo, hi = extrema(eachindex(v))
for i = lo+1:hi
j = i
x = v[i]
while j > lo && x < v[j-1]
count += 1
v[j] = v[j-1]
j -= 1
end
v[j] = x
end
count
end
K = 1:6
M = 4 .* K
N = M .* 4^7
swaps = [count_insertion_sort!(comb!(repeat(1:m, 4^7))) for m in M]
using Plots
plot(N, swaps, label="actual swaps", xlabel="n", ylabel="swaps", legend=:topleft)
plot!(N, .024N.^2, label="theoretical minimum")
Results
[image: Screen Shot 2022-10-05 at 5 02 03 PM]
<https://user-images.githubusercontent.com/60898866/194047014-8a96fddb-60da-4f81-accc-26f05375221d.png>
------------------------------
The proof conveniently provides us with a pathological input to test. So,
even more empirically, we can simply measure runtime.
Code
# multiply by a large number ot avoid dispatch to counting sort
make_vector(m) = 4^7*repeat(1:m, 4^7)
x = 1:20
n = 4^7*x
comb = [(x = make_vector(m); @Elapsed(sort!(x; alg=CombSort))) for m in x]
default = [(x = make_vector(m); @Elapsed(sort!(x ))) for m in x]
theory = .024n.^2 / 1.6e9 # 1.6 ghz clock speed
plot(n, comb, label="comb sort", xlabel="n", ylabel="time (s)", legend=:topleft)
plot!(n, default, label="default sort")
plot!(n, theory, label="theoretical minimum")
Results
[image: Screen Shot 2022-10-05 at 5 18 43 PM]
<https://user-images.githubusercontent.com/60898866/194048696-d4f0adc4-7ec7-4cbc-8238-2197618731c9.png>
—
Reply to this email directly, view it on GitHub
<#54 (review)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AABHKEW56FQQ7SBVG2RIR7DWBVQ3TANCNFSM5O2OTAQA>
.
You are receiving this because you authored the thread.Message ID:
***@***.***
com>
|
|
I agree that reference must have been talking about nongeometric gap sequences if it found subquadratic runtimes (i.e. some special way of reducing the intervals). I suspect that, like shell sort, the ideal gap sequence is hard to compute. The algorithm as written (with a geometric gap sequence) also has Θ(n^2) average case runtime. The proof is similar to the worst case proof, but gives a much lower constant factor. Take arbitrary integer Now consider which elements fall in the first quartile. Obviously, one quarter do. Less obviously, consider how many elements of a given view fall above the median. Specifically, what are the odds that more than three quarters of a view falls in the first quartile? This is not an easy question to answer precisely. Note that the answer depends on Consider the on average But before we write off this algorithm as quadratic and suitable only for small vectors, we should compute This is a proof that this algorithm has quadratic asymptotic runtime, but due to a very low constant factor, the proof is empirically vacuous. |
Co-authored-by: Lilith Orion Hafner <lilithhafner@gmail.com>
Co-authored-by: Lilith Orion Hafner <lilithhafner@gmail.com>
|
@LilithHafner that's awesome, this algorithm really seems to require some different ways of thinking in order to analyze it, not just figuring out the "mechanics"... I can't see any attachments, is the article you referred to somewhere on-line? Regarding the impact of the interval choices, I imagine it would be nice to find a way to ensure we don't stick to a partition of views like you describe. I also imagine the main issue is whether we can guarantee that once we reach interval I've also been thinking about this algorithm compared to sorting networks. The geometric interval decay would serve as a kind of heuristic in the design of the complete sorting network for the full input. Knowing that there must be "optimal", n log n sorting networks for any input size, the remaining question would be what modifications would we need to perform to the original network in order to implement an optimal network? Could there really be a systematic limitation in this approach that puts it decidedly outside the set of optimal sorting networks? Of course insertion sort is not a sorting network, this is just how I've been thinking about this lately. |
|
I made an experiment here trying to understand what the "comb" passes do to the data, and what's the effect of the partitioning. I ran the algorithm without the final insertion sort on random permutations of 1:Nlen, with Nlen=10007 (a prime number) and Nlen=2^13, on a sample of 1001 inputs. I'm plotting here statistics of what I'm calling the "error", which is the vector minus 1:Nlen, or the distance from the value to where it should be in the sorted array. The general impression I have is that with the partition, it seems we actually get a hard limit on the error, although the distribution is broader. With the prime input, the distribution is more concentrated, but there can be a few strong peaks. So without the partition we can remain with a few values way far from where they should be, what I believe are called "turtles" in the context of bubble sort. Other than that, values tend to be closer to where they should in general. Anyways, there seems to be some interesting compromise between the two cases. Partitioning leaves us further from the desired position, but seems to guarantee a maximum error.
|


|
OK there seems to be no guarantee for N^13, actually!...
Here are just the general error ecdf from both cases
|




|
With the Mersenne prime 2^13-1 the differences to 2^13 are less pronounced, so the length might actually have been a larger factor here than the partitioning of the input.
This plot here highlights what the distribution of the errors looks like. 40% of the numbers are in the correct place after the "combing", and 85% within 1 step.
A histogram with logarithmic scale, perhaps the tails are exponential?... If that was the case, what would it imply to the complexity of insertion sort? |




Sorry about that: https://pdfslide.net/download/link/an-efficient-variation-of-bubble-sort |
There was a problem hiding this comment.
Your exploration of the effect of the comb pass is interesting. It seems that the theoretical problems don't really come up in random input of reasonable sizes. That's good!
If the tails were exponential (i.e. odds of an element being x places out of place is p^x for some p < 1) then that would imply that the insertion pass will run in linear time. Empirically, that seems to hold on the data you tested.
I think working on better gap sequences and/or the theory or empirical benchmarks to back them is a worthwhile pursuit if you are interested, but I also think it is a long pursuit and would prefer to merge this first, and then improve the gap sequence later, if that is okay with you.
Co-authored-by: Lilith Orion Hafner <lilithhafner@gmail.com>
|
Sure, let's merge this. If the standand deviation of that exponential distribution is linear with the input size, wouldn't that make the final insertion sort quadratic? I think a variation of this algorithm that offers n log n worst-case will probably require some big insight, there's some structural detail missing. And like I said, maybe sorting networks will offer the inspiration. In fact, maybe the best step forward trying to leverage the good parallelism we get from this code might actually be to implement a generic sorting network method such as https://en.wikipedia.org/wiki/Bitonic_sorter |
I was assuming that the coefficient for the geometric distribution was constant with input size, if it scales linearly, then that would indeed be quadratic. |
This implements the comb sort algorithm. The patch was first submitted to Julia core, but it was decided that SortingAlgorithms.jl would be a better place. JuliaLang/julia#32696
Please check previous threads for details and motivation. This algorithm was discussed in a 2019 JuliaCon presentation https://youtu.be/_bvb8X4DT90?t=402 . The main motivation to use comb sort is that the algorithm happens to lead itself very well to compiler optimizations, especially vectorization. This can be checked by running e.g.
@code_llvm sort!(rand(Int32, 2^12), 1, 2^12, CombSort, Base.Order.Forward)and looking for an instruction such asicmp slt <8 x i32>.Comb sort is a general, non-stable comparison sort that outperforms the standard quick/intro sort for 32-bit integers. It doesn't seem to outperform radix sort for that kind of element type, though. So it's not clear whether it only outperforms quick sort in the cases where radix sort is actually optimal. The motivation is that comb sort is a simple general-purpose algorithm that seems to be easily optimized by the compiler to exploit modern parallel architectures.
I'd gladly perform more benchmarks if this is desired, although it would be nice to hear specific ideas of the kind of input types and sizes we are interested in. As far as I know, none of the currently implemented algorithms had to be validated with such experiments before being merged. It would be great to hear some advice about moving forward with this contribution, if at all, since this peculiar algorithm seems to attract a high level of scrutiny, probably deserved.
All the tests right now seem to be heavily based on floating-point numbers, and here there's actually some challenges in the implementation. The core of the implementation is the function
ltminmaxwhich compares two values and returns an ordered pair using theminandmaxfunctions. This is perfect for integers and strings, but with floating-point things get weird, as usual. The results with NaNs right now are actually not even correct, although the test is passing (!). It would be great to have some advice about how to fix that, as well as how we might extend the tests.I'm very glad to have studied this algorithm using Julia, I feel it's a great showcase for the language, and it seems to epitomize modern, parallel-focused computing. I'd love to hear suggestions about how we might highlight these ideas in this patch.