Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
New issue
Have a question about this project? Sign up for a free GitHub account to open an issue and contact its maintainers and the community.
By clicking “Sign up for GitHub”, you agree to our terms of service and privacy statement. We’ll occasionally send you account related emails.
Already on GitHub? Sign in to your account
Implements the CombSort algorithm #54
Implements the CombSort algorithm #54
Changes from 12 commits
b7d344bab91a3c4afd2321114aff5a44bf36f2b897201f6d3af75499c7430433d05664b4d21d18023013135a653dbc0e033da6412File filter
Filter by extension
Conversations
Jump to
There are no files selected for viewing
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
This algorithm has quadratic worst-case runtime.
Proof
Take an arbitrary
k, letm = 4k, and letn = m*4^7. Consider the first 7 intervals for an input of lengthn:[n*(3/4)^i for i in 1:7] == [m*4^7*(3/4)^i for i in 1:7] == [m*4^(7-i)*3^i for i in 1:7]. Notice that each interval is divisible bym.Now, construct a pathological input
v = repeat(1:m, 4^7). This input has the propertyv[i] == v[i+*jm]for any intergersiandjwhich yield inbounds indices. Consequently, the first 7 passes cannot altervat all.Informal interlude: There are still a lot of low numbers near the end of the list, and the remaining passes will have a hard time moving them to the beginning because their intervals are fairly small.
Consider the elements
1:kthat fall in the final quarter ofv. There arek*4^7/4 = n/16such elements. Each of them must end up in the first quarter of the list once sorted, so they must each travel a total of at leastn/2slots (in reality they must each travel more than this, but all I claim is a lower bound).To recap, we have established
n/16elements that must travel at leastn/2slots, and that they do not travel at all in the first 7 passes. The remaining comb passes have intervals no greater than[n*(3/4)^i for i in 8:inf]. The furthest an elemental can move toward the start of the vector in a single pass is the interval size of that pass, so the furthest an element can move toward the start of the vector in all remaining passes combined issum([n*(3/4)^i for i in 8:inf]) = n*(3/4)^8 / (1 - 3/4) = 4n*(3/4)^8 < 0.401n. Thus, after all the comb passes are compete, we will still haven/16elements that have to move at least0.099nslots toward the start of the vector. Insertion sort, which can only move one swap at a time will require0.099n*n/4 > .024n^2swaps to accomplish this. Therefore, the worst case runtime of this algorithm isΩ(n^2).It is structurally impossible for this algorithm to take more than
O(n^2)time, so we can concludeΘ(n^2)is a tight asymptotic bound on the worst case runtime of this implementation of combsort. (A similar analysis holds for any geometric interval distribution).We can verify the math in this proof empirically:
code
Results
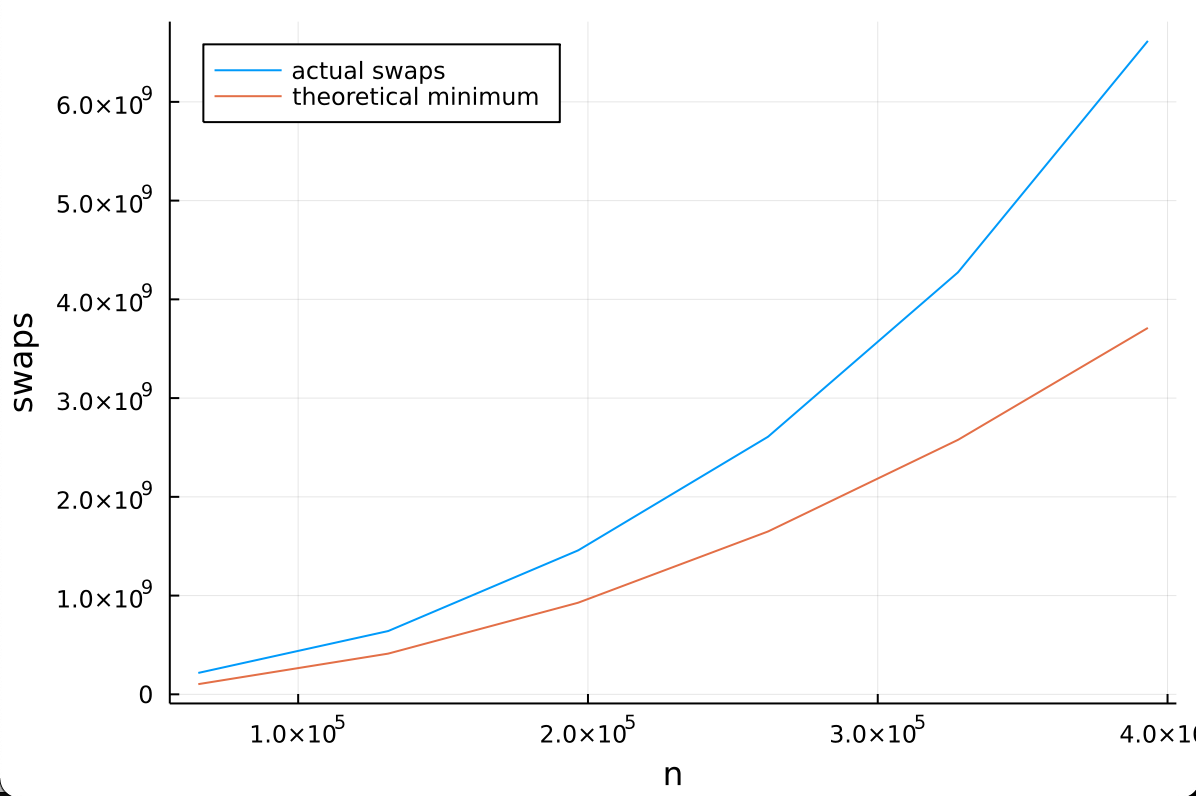
The proof conveniently provides us with a pathological input to test. So, even more empirically, we can simply measure runtime.
Code
Results