DataModel
Table of Contents
Most applications of time series data access values according to some natural grouping. For example, when accessing host metrics, it's typical to retrieve the utilization for all cores and/or CPUs at once in order to visualize them as a comparison, or compute an aggregate utilization. Other examples include inbound and outbound network traffic, or the collection of values that make up a histogram. Because this type of grouped access is so common, Newts utilizes a data model that makes storage and access of metric groups efficient, and retrieval automatic.
The Newts data model is a structure consisting of a one-to-many mapping between a unique user-selected resource ID and the sample interval timestamps, which in turn have a one-to-many relationship with the metric/value pairs that constitute the group (see Fig 1).
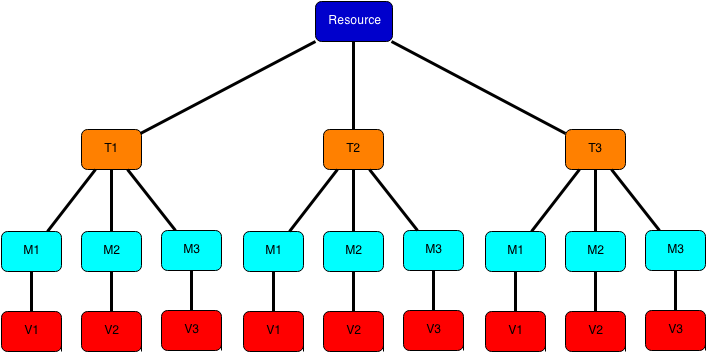
Fig. 1: Structure that facilities a range of time interval values by resource; Yields results containing the full group of persisted values.
Newts uses the wide row support of CQL to store a materialized view of the result graph contiguously on disk.
CREATE TABLE samples (
context text,
partition int,
resource text,
collected_at timestamp,
metric_name text,
value blob,
attributes map<text, text>,
PRIMARY KEY((context, partition, resource), collected_at, metric_name)
);The Cassandra partition key; The key used to distribute rows throughout a cluster, is a compound value made up of the application selected resource ID, a date-based numeric partition value, and an application-specific context name.
The partition value creates an upper bound on the amount of data that can be stored within a single Cassandra row. Higher values will result in longer (and fewer )individual reads, and less disk IO, at the expense of higher latency. Lower values result in a larger number of smaller, concurrent reads and greater disk IO, (but with potentially lower latency).
The partition period defaults to 7 days, and is configuration on an application context basis.
A sample is the basic unit of storage in Newts; Samples represent the value of a resources metric at some instance in time. Irrespective of API, persisted samples contain a number of important attributes.
Resource IDs are the domain of applications that store data in Newts, and should be selected with care.
Every metric that shares a resource ID is implicitly part of the same group. Such metrics will be stored together, and returned as a group when queried. Newts does not place any constraints on the size of such a group, a metric group can contain as few as one metric, or as many as the underlying storage will accommodate.
A well chosen group is one that optimizes for the common case, containing all of the metrics necessary to fulfill some use case the majority of time, (but doesn't preclude occasionally filtering out a subset for other uses). If your use case is graphing, then chances are there is a 1:1 correlation between the group a resource represents, and a corresponding graph.
By convention, multi-part resource IDs are colon-delimited (:).
Timestamps are 64bit integers representing the number of milliseconds since the Unix epoch.
Metrics names are identifiers of a value, and are unique to a given resource.
Metric types are used to describe the type of the corresponding value, currently one of:
COUNTER- Used for continuously incrementing counters; A data source that never
decreases, except when the counter overflows. Newts aggregation pipeline
will convert
COUNTERtypes to a rate automatically, and take overflows into account. GAUGE- Used for values that are represented as-is. For example, temperature, or stock price.
ABSOLUTE- Assumes the previous value is set to
0. DERIVE- Similar to a
COUNTERbut allows negative values. For example a bidirectional pump.
Numeric value of the sample.
Arbitrary key value pairs associated with a sample; Sample attributes are useful for associating corresponding event or state information with samples. These attributes are returned as-is in raw sample queries, and collated in aggregated measurements.