image_text_extractor is a Python-based application designed to extract text from images.
- GUI for image loading and text extraction
- Manual selection of regions of interest
- Text extraction from selected regions
Note: This project was only tested on Windows.
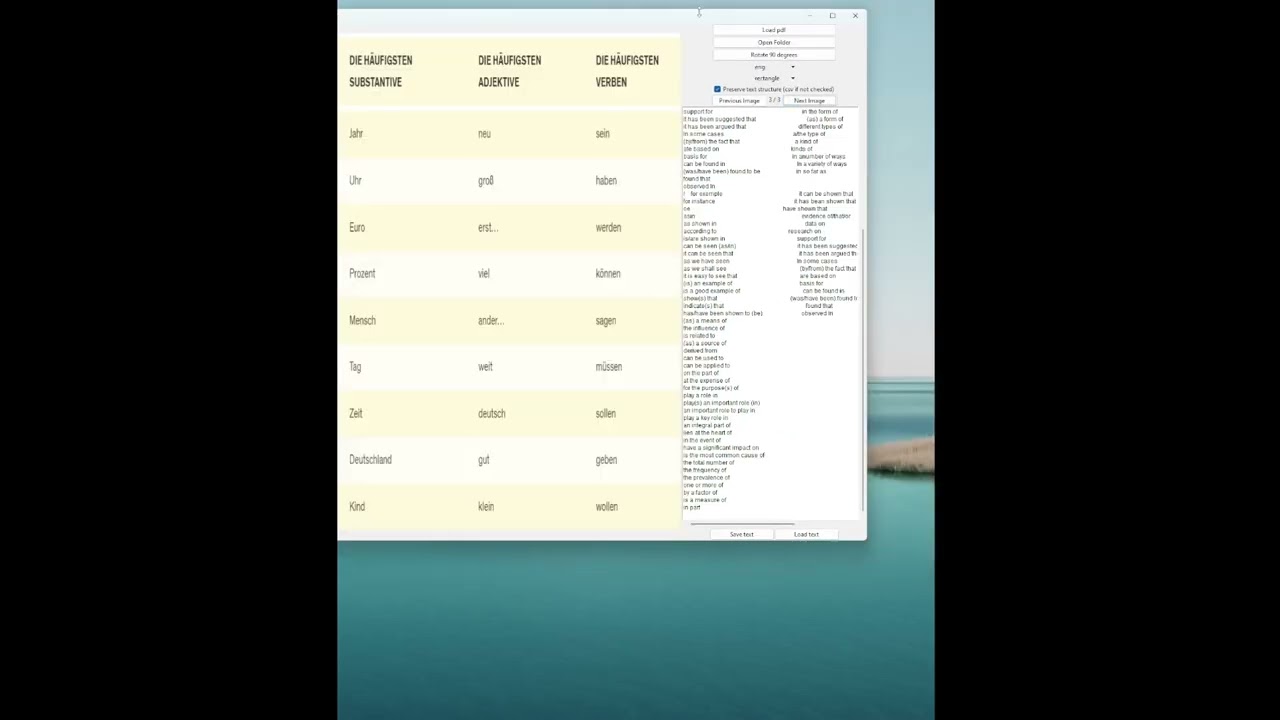




- Image Loading: Load images from a folder or individual files.
- Mask Drawing Modes: Supports freehand and rectangle drawing modes for selecting regions of interest.
- Text Extraction: Extract text from selected regions using Tesseract OCR.
- Text Copying: Copy extracted text to a text field with options to preserve text structure.
- File Dialogs: Open text files to display their content in the GUI.
- Python 3.x
- Tesseract OCR
- Python packages:
opencv-python,pillow,pytesseract,numpy,matplotlib
To install the required packages, run the following command:
pip install -r requirements.txt-
Windows:
- Download the Tesseract installer from Tesseract at UB Mannheim.
- Run the installer and follow the instructions.
- Add the Tesseract installation path (e.g.,
C:\Program Files\Tesseract-OCR) to your system's PATH environment variable.
-
macOS (not tested):
- Install Tesseract using Homebrew:
brew install tesseract
- Install Tesseract using Homebrew:
-
Linux (not tested):
- Install Tesseract using your package manager. For example, on Ubuntu:
sudo apt-get install tesseract-ocr
- Install Tesseract using your package manager. For example, on Ubuntu:
To install additional language packs for Tesseract:
-
Windows:
- Download the desired language pack (e.g.,
fra.traineddatafor French) from the Tesseract GitHub repository. - Copy the downloaded
.traineddatafile to thetessdatadirectory of your Tesseract installation (e.g.,C:\Program Files\Tesseract-OCR\tessdata).
- Download the desired language pack (e.g.,
-
macOS (not tested):
- Use Homebrew to install the language pack:
brew install tesseract-lang
- Use Homebrew to install the language pack:
-
Linux (Ubuntu) (not tested):
- Use your package manager to install the language pack. For example, to install the French language pack:
sudo apt-get install tesseract-ocr-fra
- Use your package manager to install the language pack. For example, to install the French language pack:
- Run the Application: Execute the
extractor.pyscript to start the application. - Load Images: Use the file dialog to load images from a folder.
- Select Drawing Mode: Choose between freehand and rectangle drawing modes.
- Draw on Image: Draw on the image to select the region of interest.
- Extract Text: Extract text from the selected region and copy it to the text field.
- Save or Copy Text: Save the extracted text or copy it to the clipboard.
Note: Ensure to update the tesseract_cmd path in the code to match your Tesseract installation path
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'