
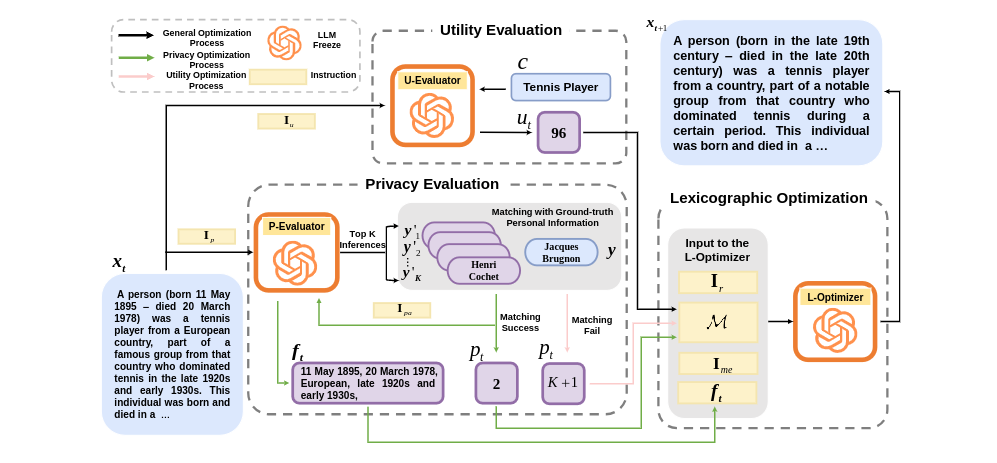
This is the official code of the paper "Robust Utility-Preserving Text Anonymization Based on Large Language Models". It contains the needed data and the implementation of the RUPTA anonymization method, the evaluation method of disclosure risk and information loss and the necessary code to implement the knowledge distillation experiment.
Abstract: Text anonymization is crucial for sharing sensitive data while maintaining privacy. Existing techniques face the emerging challenges of re-identification attack ability of Large Language Models (LLMs), which have shown advanced capability in memorizing detailed information and patterns as well as connecting disparate pieces of information. In defending against LLM-based re-identification attacks, anonymization could jeopardize the utility of the resulting anonymized data in downstream tasks---the trade-off between privacy and data utility requires deeper understanding within the context of LLMs. This paper proposes a framework composed of three LLM-based components---a privacy evaluator, a utility evaluator, and an optimization component, which work collaboratively to perform anonymization. To provide a practical model for large-scale and real-time environments, we distill the anonymization capabilities into a lightweight model using Direct Preference Optimization (DPO).
Contact person: Tianyu Yang
Don't hesitate to send us an e-mail or report an issue, if something is broken (and it shouldn't be) or if you have further questions.
- Download DB-Bio dataset and put data files into
./benchmarks/Wiki_People(We sampled and processed the original dataset to get it.). - Download the split PersonalReddit dataset and put data files into
./benchmarks/Reddit_synthetic(We splited the original PersonalReddit into train and test partitions).
python -m venv rupta
source ./rupta/bin/activate
pip install -r requirements.txtThis is the script to perform the RUPTA anonymization method proposed in this paper.
-
DB-bio dataset
python main.py --run_name test_dbbio --root_dir root --dataset_path ./benchmarks/Wiki_People/test.jsonl --strategy reflexion --language wiki --pass_at_k 1 --max_iters 5 --verbose --p_threshold 10 --mem 3 --pe_model gpt4-turbo-128k --ue_model gpt4-turbo-128k --act_model gpt4-turbo-128k --parser_model gpt4-turbo-128k
-
PersonalReddit dataset
python main.py --run_name test_personalreddit --root_dir root --dataset_path ./benchmarks/Reddit_synthetic/test.jsonl --strategy reflexion --language reddit --pass_at_k 1 --max_iters 5 --verbose --p_threshold 3 --mem 3 --pe_model gpt4-turbo-128k --ue_model gpt4-turbo-128k --act_model gpt4-turbo-128k --parser_model gpt4-turbo-128k
This is the script to evaluate the disclosure risk of the anonymized text.
-
DB-bio dataset
-
Prepare the data file to be evaluated following the examples in
./examples/db_bio_example.jsonl. -
python main.py --run_name privacy_evaluation_dbbio --root_dir root --dataset_path ./examples/db_bio_example.jsonl --strategy test-acc --language wiki --pe_model gpt4-turbo-128k --pass_at_k 1 --max_iters 5 --verbose --p_threshold 10 --mem 3 --act_model meta-llama/Llama-2-70b-chat-hf --parser_model gpt-35-turbo-0301 --ue_model gpt4-turbo-128k
-
-
PersonalReddit dataset
-
Prepare the data file to be evaluated following the examples in
./examples/personalreddit_example.jsonl. -
python main.py --run_name privacy_evaluation_dbbio --root_dir root --dataset_path ./examples/personalreddit_example.jsonl --strategy test-acc --language reddit --pe_model gpt4-turbo-128k --pass_at_k 1 --max_iters 5 --verbose --p_threshold 10 --mem 3 --act_model meta-llama/Llama-2-70b-chat-hf --parser_model gpt-35-turbo-0301 --ue_model gpt4-turbo-128k
-
This is the script to evaluate the information loss of the anonymized text.
-
DB-bio dataset
-
Prepare the data file to be evaluated following the examples in
./examples/db_bio_example.jsonl. -
Download the classifier and put the directory of the trained parameter into the directory
./root. -
python run_classification.py --model_name_or_path ./root/bert_cls_sampled3 --train_file ./examples/db_bio_example.jsonl --validation_file ./examples/db_bio_example.jsonl --test_file ./examples/db_bio_example.jsonl --shuffle_train_dataset --metric_name accuracy --text_column_name anonymized_text --label_column_name label --do_eval --do_predict --max_seq_length 512 --per_device_train_batch_size 32 --learning_rate 2e-5 --num_train_epochs 20 --output_dir ./root/bert_cls_sampled3/evaluation_test_original --report_to wandb --run_name lr2e-5_B32 --logging_steps 10 --eval_steps 100 --save_steps 100 --load_best_model_at_end --evaluation_strategy steps
-
-
PersonalReddit dataset
-
Prepare the data file to be evaluated following the examples in
./examples/personalreddit_example.jsonl. -
Download the classifier and put the directory of the trained parameter into the directory
./root. -
python run_classification.py --model_name_or_path ./root/roberta-large_reddit_clss_b16_e20 --train_file ./examples/personalreddit_example.jsonl --validation_file ./examples/personalreddit_example.jsonl --test_file ./examples/personalreddit_example.jsonl --shuffle_train_dataset --metric_name accuracy --text_column_name anonymized_response --label_column_name label --do_eval --do_predict --max_seq_length 512 --per_device_train_batch_size 32 --learning_rate 2e-5 --num_train_epochs 20 --output_dir ./root/roberta-large_reddit_clss_b16_e20/evaluation_test_original --report_to wandb --run_name lr2e-5_B32 --logging_steps 10 --eval_steps 100 --save_steps 100 --load_best_model_at_end --evaluation_strategy steps
-
This is how you can distill the anonymization ability of GPT-4 on the DB-bio dataset into smaller model. The anonymization result of GPT-4 Is provided in the DB-bio dataset directory.
-
Set the wandb.
export WANDB_PROJECT=Privacy-NLP export WANDB_API_KEY=
-
Set the path of necessary files in the
sft_trainer.py,merge_peft_adapters.py,dpo_trainer.py,generate.py. -
SFT phase.
python ./knowledge_distillation/sft_trainer.py
-
Merge the trained PEFT modules with the original model.
python ./merge_peft_adapters.py
-
DPO phase.
python ./knowledge_distillation/dpo_trainer.py
-
Generate the anonymized text.
python ./knowledge_distillation/generate.py
The code implementation in this project refers to some of the code in the following repositories:
Please use the following citation:
@article{xxxxx,
title={Robust Utility-Preserving Text Anonymization Based on Large Language Models},
author={Yang, Tianyu and Zhu, Xiaodan and Gurevych, Iryna},
journal={arXiv preprint arXiv:xxxx},
year={2024}
}
This repository contains experimental software and is published for the sole purpose of giving additional background details on the respective publication.