This project was given to me as an assignment as part of a course during my computer science bechelor dgree. In the course I used AWS and Hadoop to work with large amount of data.
In this assignment I generated a knowledge-base for Hebrew word-prediction system, based on Google 3-Gram Hebrew dataset, using Amazon Elastic Map-Reduce (EMR) and Hadoop. The produced knowledge-base indicates the probability of each word trigram found in the corpus.
In this assignment, I implemented a held out method, named deleted estimation.
Held out estimators divide the training data (the corpus) into two parts, build initial estimates by doing counts on one part, and then use the other pool of held out data to refine those estimates.
The deleted estimation method, for instance, uses a form of two-way cross validation, as follows:
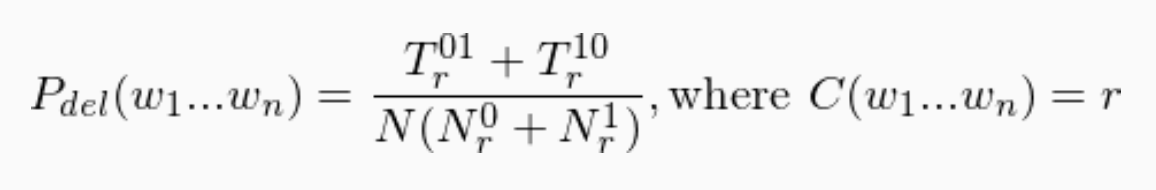
Where:
- N is the number of n-grams in the whole corpus.
- Nr0 is the number of n-grams occuring r times in the first part of the corpus.
- Tr01 is the total number of those n-grams from the first part (those of Nr0) in the second part of the corpus.
- Nr1 is the number of n-grams occuring r times in the second part of the corpus.
- Tr10 is the total number of those n-grams from the second part (those of Nr1) in the first part of the corpus.