


![]()
![]()
![]()
![]()


Starwhale是一个 MLOps/LLMOps平台,面向机器学习项目提供研发运营管理能力,建立标准化的模型开发、测试、部署和运营流程,连接业务团队、AI团队和运营团队。解决机器学习过程中模型迭代周期长、团队协作、人力资源浪费等问题。
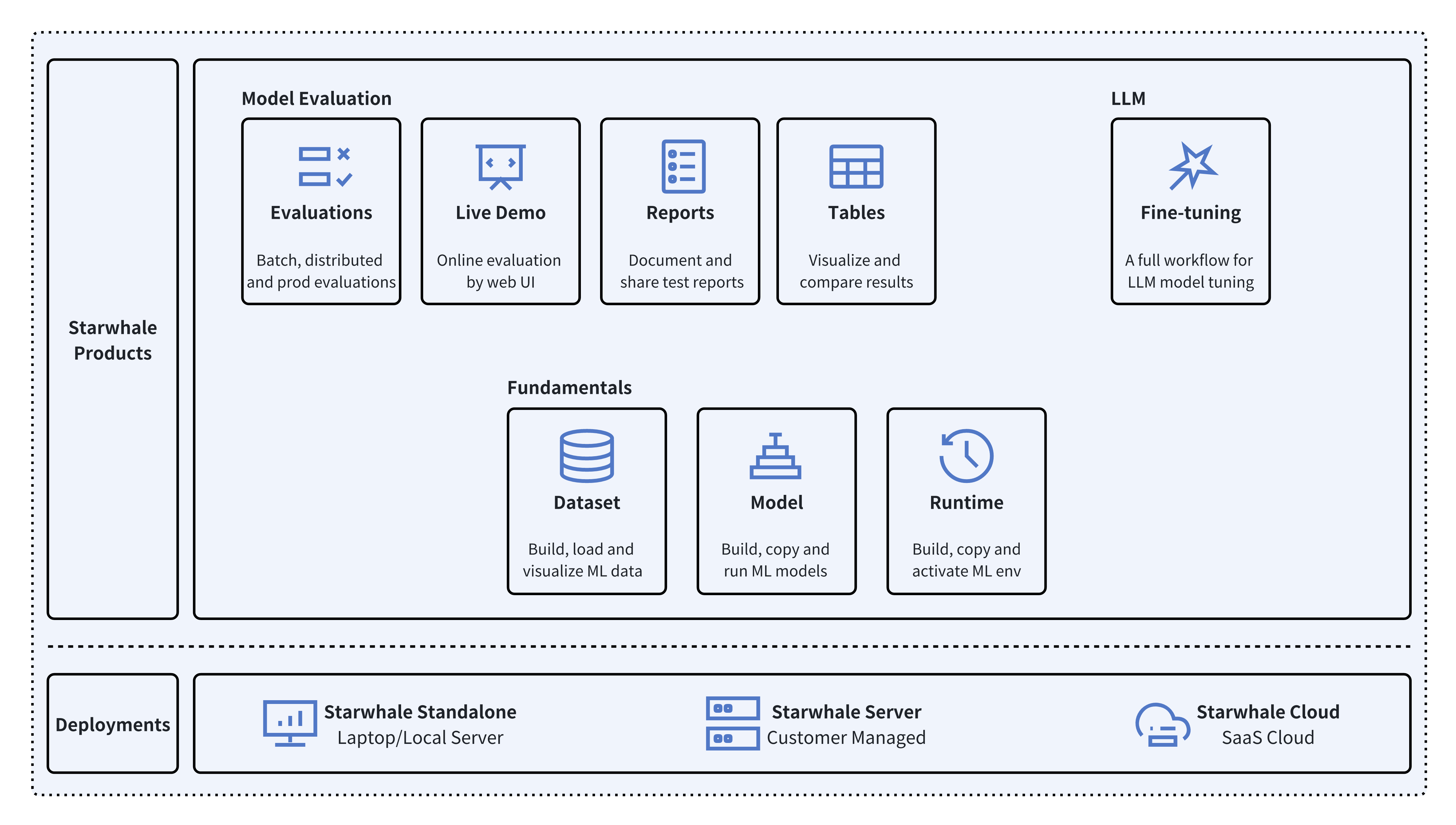
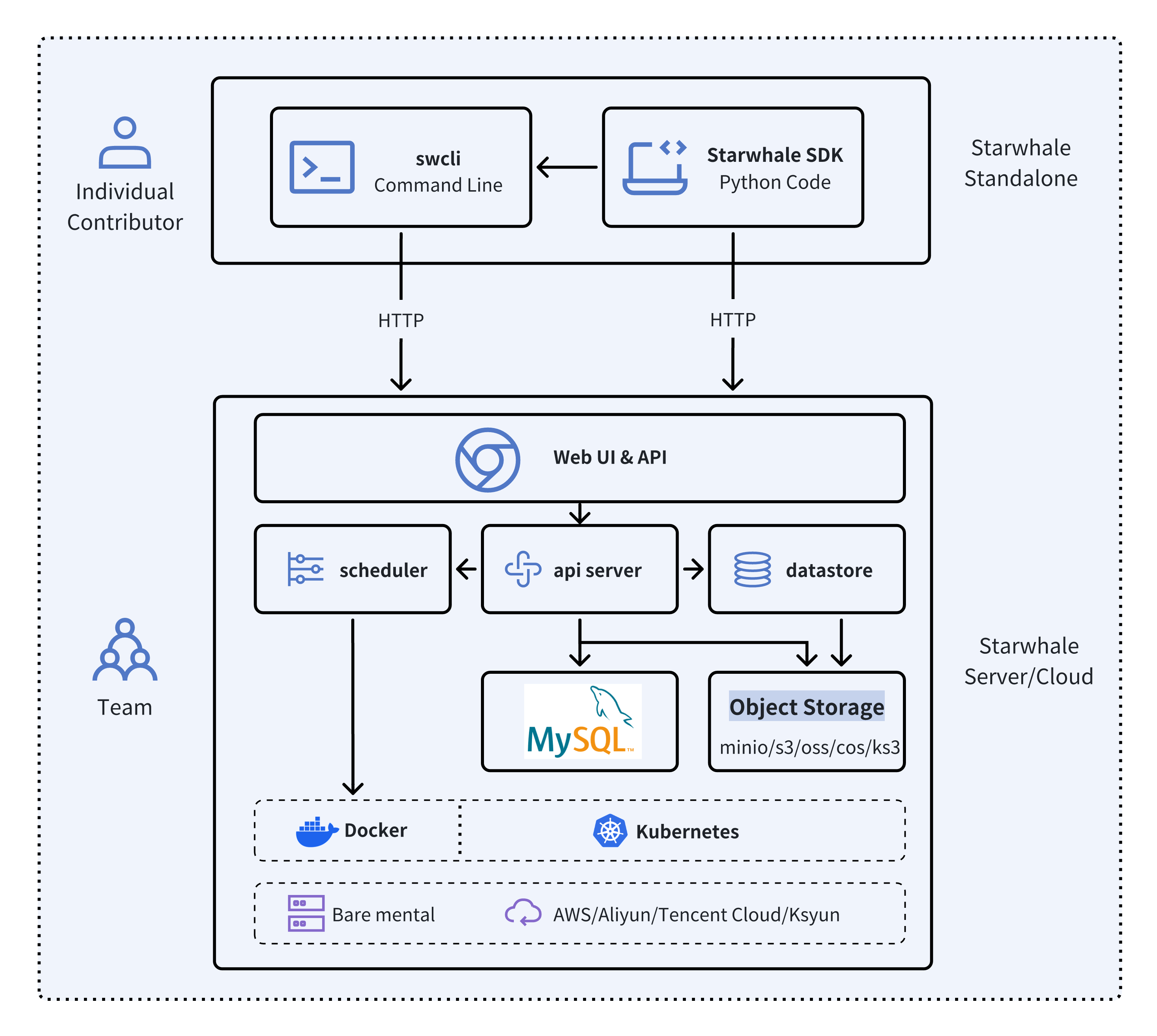
Starwhale提供Standalone, Server 和 Cloud 三种实例方式,满足单机环境开发,私有化集群部署和Starwhale团队托管的云服务多种部署场景。
- 🐥 Standalone - 部署在本地开发环境中,通过 swcli 命令行工具进行管理,满足开发调试需求。
- 🦅 Server - 部署在私有数据中心里,依赖 Kubernetes 集群,提供集中化的、Web交互式的、安全的服务。
- 🦉 Cloud - 托管在公共云上的服务,访问地址为https://cloud.starwhale.cn,由 Starwhale 团队负责运维,无需安装,注册账户后即可使用。
Starwhale 抽象了模型、数据集和运行时作为平台的根基,并在此基础上提供满足特定领域的功能需求:
- 🔥 Models Evaluation - Starwhale 模型评测能让用户通过SDK写少量的Python 代码就能实现复杂的、生产级别的、分布式的模型评测任务。
- 🌟 Live Demo - 能够通过Web UI方式对模型进行在线评测。
- 🌊 LLM Fine-tuning - 提供面向LLM的全流程模型微调工具链,包括模型微调,批量评测对比,在线评测对比和模型发布功能。
Starwhale 同时也是一个开源的平台,使用 Apache-2.0 协议。 Starwhale 框架是易于理解的,能非常容易的进行二次开发。
Starwhale 数据集能够高效的数据存储、数据加载和数据可视化,是一款面向ML/DL领域的数据管理工具。

import torch
from starwhale import dataset, Image
# build dataset for starwhale cloud instance
with dataset("https://cloud.starwhale.cn/project/starwhale:public/dataset/test-image", create="empty") as ds:
for i in range(100):
ds.append({"image": Image(f"{i}.png"), "label": i})
ds.commit()
# load dataset
ds = dataset("https://cloud.starwhale.cn/project/starwhale:public/dataset/test-image")
print(len(ds))
print(ds[0].features.image.to_pil())
print(ds[0].features.label)
torch_ds = ds.to_pytorch()
torch_loader = torch.utils.data.DataLoader(torch_ds, batch_size=5)
print(next(iter(torch_loader)))Starwhale 模型是一种机器学习模型的标准包格式,可用于多种用途,例如模型微调、模型评估和在线服务。 Starwhale 模型包含模型文件、推理代码、配置文件等等。

# model build
swcli model build . --module mnist.evaluate --runtime pytorch/version/v1 --name mnist
# model copy from standalone to cloud
swcli model cp mnist https://cloud.starwhale.cn/project/starwhale:public
# model run
swcli model run --uri mnist --runtime pytorch --dataset mnist
swcli model run --workdir . --module mnist.evaluator --handler mnist.evaluator:MNISTInference.cmpStarwhale 运行时能够针对运行Python程序,提供一种可复现、可分享的运行环境。使用 Starwhale 运行时,可以非常容易的与他人分享,并且能在 Starwhale Server 和 Starwhale Cloud 实例上使用 Starwhale 运行时。

# build from runtime.yaml, conda env, docker image or shell
swcli runtime build --yaml runtime.yaml
swcli runtime build --conda pytorch --name pytorch-runtime --cuda 11.4
swcli runtime build --docker pytorch/pytorch:1.9.0-cuda11.1-cudnn8-runtime
swcli runtime build --shell --name pytorch-runtime
# runtime activate
swcli runtime activate pytorch
# integrated with model and dataset
swcli model run --uri test --runtime pytorch
swcli model build . --runtime pytorch
swcli dataset build --runtime pytorchStarwhale 模型评测能让用户通过SDK写少量的Python 代码就能实现复杂的、生产级别的、分布式的模型评测任务。
import typing as t
import gradio
from starwhale import evaluation
from starwhale.api.service import api
def model_generate(image):
...
return predict_value, probability_matrix
@evaluation.predict(
resources={"nvidia.com/gpu": 1},
replicas=4,
)
def predict_image(data: dict, external: dict) -> None:
return model_generate(data["image"])
@evaluation.evaluate(use_predict_auto_log=True, needs=[predict_image])
def evaluate_results(predict_result_iter: t.Iterator):
for _data in predict_result_iter:
...
evaluation.log_summary({"accuracy": 0.95, "benchmark": "test"})
@api(gradio.File(), gradio.Label())
def predict_view(file: t.Any) -> t.Any:
with open(file.name, "rb") as f:
data = Image(f.read(), shape=(28, 28, 1))
_, prob = predict_image({"image": data})
return {i: p for i, p in enumerate(prob)}Starwhale 模型微调提供针对大语言模型(LLM)的全流程微调工具链,包括模型批量评测、在线评测和模型发布等功能。Starwhale 模型评测的 Python SDK 非常简单,例子如下:
import typing as t
from starwhale import finetune, Dataset
from transformers import Trainer
@finetune(
resources={"nvidia.com/gpu":4, "memory": "32G"},
require_train_datasets=True,
require_validation_datasets=True,
model_modules=["evaluation", "finetune"],
)
def lora_finetune(train_datasets: t.List[Dataset], val_datasets: t.List[Dataset]) -> None:
# init model and tokenizer
trainer = Trainer(
model=model, tokenizer=tokenizer,
train_dataset=train_datasets[0].to_pytorch(), # convert Starwhale Dataset into Pytorch Dataset
eval_dataset=val_datasets[0].to_pytorch())
trainer.train()
trainer.save_state()
trainer.save_model()
# save weights, then Starwhale SDK will package them into Starwhale Model前置条件: Python 3.7~3.11,运行 Linux 或 macOS 操作系统上。
python3 -m pip install starwhaleStarwhale Server 以 Docker 镜像的形式发布。您可以直接使用 Docker 运行,也可以部署到 Kubernetes 集群上。对于本地笔记本电脑环境,推荐使用 swcli 命令启动 Starwhale Server,该方式需要本地安装 Docker 和 Docker Compose。
swcli server start我们使用 Minikube 作为Starwhale 平台hello world例子,来展示 Starwhale 的典型工作流程。
- 如果使用本地Python环境,请参考 Standalone 快速入门文档。
- 如果使用Google Colab环境,请参考 jupyter notebook 例子。
- 如果想运行在私有化的 Starwhale Server 实例中,请阅读 Server 安装 和 Server 快速入门。
- 如果想运行在 Starwhale Cloud 中,请阅读 Cloud 快速入门文档。
-
🚀 LLM:
- 🐊 OpenSource LLMs Leaderboard: Evaluation, Code
- 🐢 Llama2: Run llama2 chat in five minutes, Code
- 🦎 Stable Diffusion: Cloud Demo, Code
- 🦙 LLAMA evaluation and fine-tune
- 🎹 Text-to-Music: Cloud Demo, Code
- 🍏 Code Generation: Cloud Demo, Code
-
🌋 Fine-tuning:
- 🐏 Baichuan2: Cloud Demo, Code
- 🐫 ChatGLM3: Cloud Demo, Code
- 🦏 Stable Diffusion: Cloud Demo, Code
-
🦦 Image Classification:
- 🐻❄️ MNIST: Cloud Demo, Code.
- 🦫 CIFAR10
- 🦓 Vision Transformer(ViT): Cloud Demo, Code
-
🐃 Image Segmentation:
- Segment Anything(SAM): Cloud Demo, Code
-
🐦 Object Detection:
- 🦊 YOLO: Cloud Demo, Code
- 🐯 Pedestrian Detection
-
📽️ Video Recognition: UCF101
-
🦋 Machine Translation: Neural machine translation
-
🐜 Text Classification: AG News
-
🎙️ Speech Recognition: Speech Command
-
使用 Github Issue 反馈Bug 和 提交Feature Request。
-
微信公众号:
-
Starwhale 发布的制品:
- Python Package
- Helm Charts
- Docker Image: Github Packages 和 Starwhale Registry。
-
更多帮助,请您通过邮箱 developer@starwhale.ai 联系我们。

🌼👏欢迎提交PR 👍🍺. 请阅读 Starwhale 开源贡献指南。
Starwhale 使用 Apache License 2.0 协议。