diff --git a/.github/workflows/ci_cpu.yml b/.github/workflows/ci_cpu.yml
index c33d5d1c7b..98e6845381 100644
--- a/.github/workflows/ci_cpu.yml
+++ b/.github/workflows/ci_cpu.yml
@@ -7,6 +7,8 @@ on:
pull_request:
branches:
- master
+ merge_group:
+
concurrency:
group: ci-cpu-${{ github.workflow }}-${{ github.ref == 'refs/heads/master' && github.run_number || github.ref }}
diff --git a/.github/workflows/ci_gpu.yml b/.github/workflows/ci_gpu.yml
index 695c245c97..2baec7e16f 100644
--- a/.github/workflows/ci_gpu.yml
+++ b/.github/workflows/ci_gpu.yml
@@ -7,6 +7,7 @@ on:
pull_request:
branches:
- master
+ merge_group:
concurrency:
group: ci-gpu-${{ github.workflow }}-${{ github.ref == 'refs/heads/master' && github.run_number || github.ref }}
diff --git a/.github/workflows/doc-automation.yml b/.github/workflows/doc-automation.yml
index 1eb9d80847..b3ffb2b091 100644
--- a/.github/workflows/doc-automation.yml
+++ b/.github/workflows/doc-automation.yml
@@ -2,6 +2,8 @@ on:
push:
branches:
- master
+ merge_group:
+
jobs:
build_docs_job:
runs-on: ubuntu-20.04
diff --git a/.github/workflows/docker-ci.yaml b/.github/workflows/docker-ci.yaml
index a95f0da1f1..7dc17e0377 100644
--- a/.github/workflows/docker-ci.yaml
+++ b/.github/workflows/docker-ci.yaml
@@ -5,6 +5,8 @@ on:
branches: [ "master" ]
pull_request:
branches: [ "master" ]
+ merge_group:
+
jobs:
test-build-and-container:
diff --git a/.github/workflows/lint.yml b/.github/workflows/lint.yml
index a13152b59a..3ee09f42e8 100644
--- a/.github/workflows/lint.yml
+++ b/.github/workflows/lint.yml
@@ -7,6 +7,8 @@ on:
pull_request:
branches:
- master
+ merge_group:
+
jobs:
mypy:
diff --git a/.github/workflows/regression_tests_cpu.yml b/.github/workflows/regression_tests_cpu.yml
index 33f03eb54e..a7060a4d35 100644
--- a/.github/workflows/regression_tests_cpu.yml
+++ b/.github/workflows/regression_tests_cpu.yml
@@ -7,6 +7,7 @@ on:
pull_request:
branches:
- master
+ merge_group:
concurrency:
group: ci-cpu-${{ github.workflow }}-${{ github.ref == 'refs/heads/master' && github.run_number || github.ref }}
diff --git a/.github/workflows/regression_tests_gpu.yml b/.github/workflows/regression_tests_gpu.yml
index cdf0812230..ddfc08670c 100644
--- a/.github/workflows/regression_tests_gpu.yml
+++ b/.github/workflows/regression_tests_gpu.yml
@@ -7,6 +7,7 @@ on:
pull_request:
branches:
- master
+ merge_group:
concurrency:
group: ci-cpu-${{ github.workflow }}-${{ github.ref == 'refs/heads/master' && github.run_number || github.ref }}
diff --git a/docs/FAQs.md b/docs/FAQs.md
index 4c9be8a06d..348414d765 100644
--- a/docs/FAQs.md
+++ b/docs/FAQs.md
@@ -1,6 +1,7 @@
# FAQ'S
Contents of this document.
* [General](#general)
+* [Performance](#performance)
* [Deployment and config](#deployment-and-config)
* [API](#api)
* [Handler](#handler)
@@ -34,9 +35,23 @@ No, As of now only python based models are supported.
Torchserve is derived from Multi-Model-Server. However, Torchserve is specifically tuned for Pytorch models. It also has new features like Snapshot and model versioning.
### How to decode international language in inference response on client side?
-By default, Torchserve uses utf-8 to encode if the inference response is string. So client can use utf-8 to decode.
+By default, Torchserve uses utf-8 to encode if the inference response is string. So client can use utf-8 to decode.
-If a model converts international language string to bytes, client needs to use the codec mechanism specified by the model such as in https://github.com/pytorch/serve/blob/master/examples/nmt_transformer/model_handler_generalized.py#L55
+If a model converts international language string to bytes, client needs to use the codec mechanism specified by the model such as in https://github.com/pytorch/serve/blob/master/examples/nmt_transformer/model_handler_generalized.py
+
+## Performance
+
+Relevant documents.
+- [Performance Guide](performance_guide.md)
+
+### How do I improve TorchServe performance on CPU?
+CPU performance is heavily influenced by launcher core pinning. We recommend setting the following properties in your `config.properties`:
+
+```bash
+cpu_launcher_enable=true
+cpu_launcher_args=--use_logical_core
+```
+More background on improving CPU performance can be found in this [blog post](https://pytorch.org/tutorials/intermediate/torchserve_with_ipex#grokking-pytorch-intel-cpu-performance-from-first-principles).
## Deployment and config
Relevant documents.
@@ -97,7 +112,7 @@ TorchServe looks for the config.property file according to the order listed in t
- [models](configuration.md): Defines a list of models' configuration in config.property. A model's configuration can be overridden by [management API](management_api.md). It does not decide which models will be loaded during TorchServe start. There is no relationship b.w "models" and "load_models" (ie. TorchServe command line option [--models](configuration.md)).
-###
+###
## API
Relevant documents
@@ -133,7 +148,7 @@ Refer to [default handlers](default_handlers.md) for more details.
### Is it possible to deploy Hugging Face models?
Yes, you can deploy Hugging Face models using a custom handler.
-Refer to [HuggingFace_Transformers](https://github.com/pytorch/serve/blob/master/examples/Huggingface_Transformers/README.md#huggingface-transformers) for example.
+Refer to [HuggingFace_Transformers](https://github.com/pytorch/serve/blob/master/examples/Huggingface_Transformers/README.md#huggingface-transformers) for example.
## Model-archiver
Relevant documents
diff --git a/docs/README.md b/docs/README.md
index 8055e661ff..f44e6c56cc 100644
--- a/docs/README.md
+++ b/docs/README.md
@@ -52,4 +52,4 @@ TorchServe is a performant, flexible and easy to use tool for serving PyTorch ea
* [TorchServe on Kubernetes](https://github.com/pytorch/serve/blob/master/kubernetes/README.md#torchserve-on-kubernetes) - Demonstrates a Torchserve deployment in Kubernetes using Helm Chart supported in both Azure Kubernetes Service and Google Kubernetes service
* [mlflow-torchserve](https://github.com/mlflow/mlflow-torchserve) - Deploy mlflow pipeline models into TorchServe
* [Kubeflow pipelines](https://github.com/kubeflow/pipelines/tree/master/samples/contrib/pytorch-samples) - Kubeflow pipelines and Google Vertex AI Managed pipelines
-* [NVIDIA MPS](mps.md) - Use NVIDIA MPS to optimize multi-worker deployment on a single GPU
+* [NVIDIA MPS](nvidia_mps.md) - Use NVIDIA MPS to optimize multi-worker deployment on a single GPU
diff --git a/docs/contents.rst b/docs/contents.rst
index f23039ac03..a2616f0192 100644
--- a/docs/contents.rst
+++ b/docs/contents.rst
@@ -16,7 +16,7 @@
model_zoo
request_envelopes
server
- mps
+ nvidia_mps
snapshot
torchserve_on_win_native
torchserve_on_wsl
diff --git a/docs/index.rst b/docs/index.rst
index 3b41e704c3..d8ee4ee63c 100644
--- a/docs/index.rst
+++ b/docs/index.rst
@@ -56,6 +56,13 @@ What's going on in TorchServe?
:link: performance_guide.html
:tags: Performance,Troubleshooting
+.. customcarditem::
+ :header: Large Model Inference
+ :card_description: Serving Large Models with TorchServe
+ :image: https://raw.githubusercontent.com/pytorch/serve/master/docs/images/ts-lmi-internal.png
+ :link: large_model_inference.html
+ :tags: Large-Models,Performance
+
.. customcarditem::
:header: Troubleshooting
:card_description: Various updates on Torcherve and use cases.
diff --git a/docs/mps.md b/docs/nvidia_mps.md
similarity index 92%
rename from docs/mps.md
rename to docs/nvidia_mps.md
index 4b10048435..063b62db53 100644
--- a/docs/mps.md
+++ b/docs/nvidia_mps.md
@@ -60,7 +60,7 @@ Please note that we set the concurrency level to 600 which will make sure that t
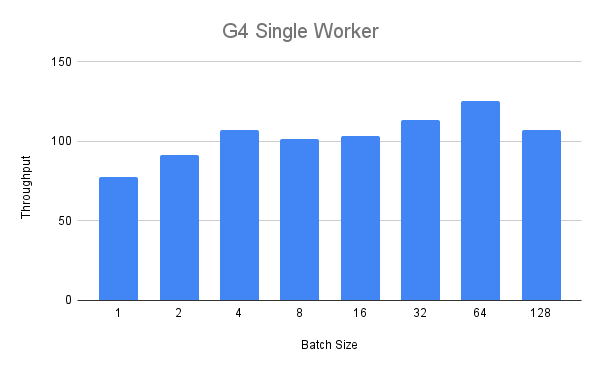
We first perform the single worker benchmark for the G4 instance.
In the figure below we see that up to a batch size of four we see a steady increase of the throughput over the batch size.
-
+
Next, we increase the number of workers to two in order to compare the throughput with and without MPS running.
To enable MPS for the second set of runs we first set the exclusive processing mode for the GPU and then start the MPS daemon as shown above.
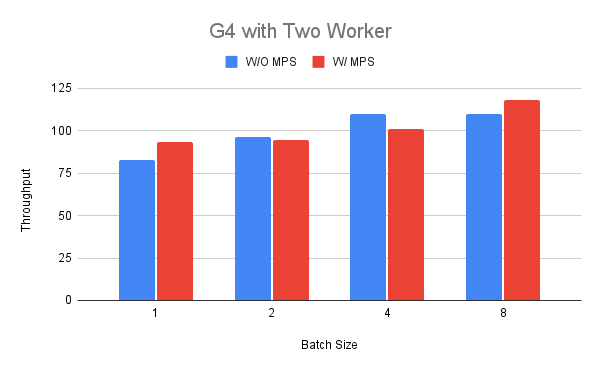
@@ -69,19 +69,19 @@ We select the batch size between one and eight according to our previous finding
In the figure we can see that the performance in terms of throughput can be better in case of batch size 1 and 8 (up to +18%) while it can be worse for others (-11%).
An interpretation of this result could be that the G4 instance has not many resources to share when we run a BERT model in one of the workers.
-
+
### P3 instance
Next, we will run the same experiment with the bigger p3.2xlarge instance.
With a single worker we get the following throughput values:
-
+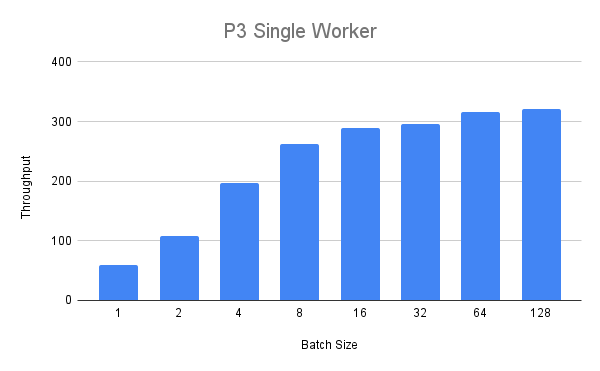
We can see that the throughput steady increases but for a batch size over eight we see diminishing returns.
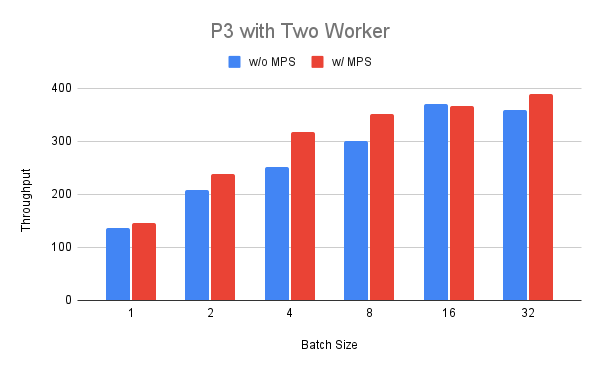
Finally, we deploy two workers on the P3 instance and compare running them with and without MPS.
We can see that for batch size between 1 and 32 the throughput is consistently higher (up to +25%) for MPS enabled with the exception of batch size 16.
-
+
## Summary
In the previous section we saw that by enabling MPS for two workers running the same model we receive mixed results.
diff --git a/docs/performance_checklist.md b/docs/performance_checklist.md
new file mode 100644
index 0000000000..d984ed37e4
--- /dev/null
+++ b/docs/performance_checklist.md
@@ -0,0 +1,38 @@
+# Model Inference Optimization Checklist
+
+This checklist describes some steps that should be completed when diagnosing model inference performance issues. Some of these suggestions are only applicable to NLP models (e.g., ensuring the input is not over-padded and sequence bucketing), but the general principles are useful for other models too.
+
+## General System Optimizations
+
+- Check the versions of PyTorch, Nvidia driver, and other components and update to the latest compatible releases. Oftentimes known performance bugs have already been fixed.
+
+- Collect system-level activity logs to understand the overall resource utilizations. It’s useful to know how the model inference pipeline is using the system resources at a high level, as the first step of optimization. Even simple CLI tools such as nvidia-smi and htop would be helpful.
+
+- Start with a target with the highest impact on performance. It should be obvious from the system activity logs where the biggest bottleneck is – look beyond model inference, as pre/post processing can be expensive and can affect the end-to-end throughput just as much.
+
+- Quantify and mitigate the influence of slow I/O such as disk and network on end-to-end performance. While optimizing I/O is out of scope for this checklist, look for techniques that use async, concurrency, pipelining, etc. to effectively “hide” the cost of I/O.
+
+- For model inference on input sequences of dynamic length (e.g., transformers for NLP), make sure the tokenizer is not over-padding the input. If a transformer was trained with padding to a constant length (e.g., 512) and deployed with the same padding, it would run unnecessarily slow (orders of magnitude) on short sequences.
+
+- Vision models with input in JPEG format often benefit from faster JPEG decoding on CPU such as libjpeg-turbo and Pillow-SIMD, and on GPU such as torchvision.io.decode_jpeg and Nvidia DALI.
+As this [example](https://colab.research.google.com/drive/1NMaLS8PG0eYhbd8IxQAajXgXNIZ_AvHo?usp=sharing) shows, Nvidia DALI is about 20% faster than torchvision, even on an old K80 GPU.
+
+## Model Inference Optimizations
+
+Start model inference optimization only after other factors, the “low-hanging fruit”, have been extensively evaluated and addressed.
+
+- Use fp16 for GPU inference. The speed will most likely more than double on newer GPUs with tensor cores, with negligible accuracy degradation. Technically fp16 is a type of quantization but since it seldom suffers from loss of accuracy for inference it should always be explored. As shown in this [article](https://docs.nvidia.com/deeplearning/performance/mixed-precision-training/index.html#abstract), use of fp16 offers speed up in large neural network applications.
+
+- Use model quantization (i.e. int8) for CPU inference. Explore different quantization options: dynamic quantization, static quantization, and quantization aware training, as well as tools such as Intel Neural Compressor that provide more sophisticated quantization methods. It is worth noting that quantization comes with some loss in accuracy and might not always offer significant speed up on some hardware thus this might not always be the right approach.
+
+- Balance throughput and latency with smart batching. While meeting the latency SLA try larger batch sizes to increase the throughput.
+
+- Try optimized inference engines such as onnxruntime, tensorRT, lightseq, ctranslate-2, etc. These engines often provide additional optimizations such as operator fusion, in addition to model quantization.
+
+- Try model distillation. This is more involved and often requires training data, but the potential gain can be large. For example, MiniLM achieves 99% the accuracy of the original BERT base model while being 2X faster.
+
+- If working on CPU, you can try core pinning. You can find more information on how to work with this [in this blog post](https://pytorch.org/tutorials/intermediate/torchserve_with_ipex#grokking-pytorch-intel-cpu-performance-from-first-principles).
+
+- For batch processing on sequences with different lengths, sequence bucketing could potentially improve the throughput by 2X. In this case, a simple implementation of sequence bucketing is to sort all input by sequence length before feeding them to the model, as this reduces unnecessary padding when batching the sequences.
+
+While this checklist is not exhaustive, going through the items will likely help you squeeze more performance out of your model inference pipeline.
diff --git a/docs/performance_guide.md b/docs/performance_guide.md
index d72c31a4f2..b4ebcd47cc 100644
--- a/docs/performance_guide.md
+++ b/docs/performance_guide.md
@@ -1,6 +1,8 @@
# [Performance Guide](#performance-guide)
In case you're interested in optimizing the memory usage, latency or throughput of a PyTorch model served with TorchServe, this is the guide for you.
+We have also created a quick checklist here for extra things to try outside of what is covered on this page. You can find the checklist [here](performance_checklist.md).
+
## Optimizing PyTorch
There are many tricks to optimize PyTorch models for production including but not limited to distillation, quantization, fusion, pruning, setting environment variables and we encourage you to benchmark and see what works best for you.
@@ -42,11 +44,17 @@ TorchServe exposes configurations that allow the user to configure the number of
TorchServe On CPU
-If working with TorchServe on a CPU here are some things to consider that could improve performance:
+If working with TorchServe on a CPU you can improve performance by setting the following in your `config.properties`:
+
+```bash
+cpu_launcher_enable=true
+cpu_launcher_args=--use_logical_core
+```
+These settings improve performance significantly through launcher core pinning.
+The theory behind this improvement is discussed in [this blog](https://pytorch.org/tutorials/intermediate/torchserve_with_ipex#grokking-pytorch-intel-cpu-performance-from-first-principles) which can be quickly summarized as:
* In a hyperthreading enabled system, avoid logical cores by setting thread affinity to physical cores only via core pinning.
* In a multi-socket system with NUMA, avoid cross-socket remote memory access by setting thread affinity to a specific socket via core pinning.
-These principles can be automatically configured via an easy to use launch script which has already been integrated into TorchServe. For more information take a look at this [case study](https://pytorch.org/tutorials/intermediate/torchserve_with_ipex#grokking-pytorch-intel-cpu-performance-from-first-principles) which dives into these points further with examples and explanations from first principles.
TorchServe on GPU
@@ -61,7 +69,7 @@ While NVIDIA GPUs allow multiple processes to run on CUDA kernels, this comes wi
* The execution of the kernels is generally serialized
* Each processes creates its own CUDA context which occupies additional GPU memory
-To get around these drawbacks, you can utilize the NVIDIA Multi-Process Service (MPS) to increase performance. You can find more information on how to utilize NVIDIA MPS with TorchServe [here](mps.md).
+To get around these drawbacks, you can utilize the NVIDIA Multi-Process Service (MPS) to increase performance. You can find more information on how to utilize NVIDIA MPS with TorchServe [here](nvidia_mps.md).
NVIDIA DALI
@@ -92,3 +100,7 @@ Visit this [link]( https://github.com/pytorch/kineto/tree/main/tb_plugin) to lea
TorchServe on the Animated Drawings App
For some insight into fine tuning TorchServe performance in an application, take a look at this [article](https://pytorch.org/blog/torchserve-performance-tuning/). The case study shown here uses the Animated Drawings App form Meta to improve TorchServe Performance.
+
+Performance Checklist
+
+We have also created a quick checklist here for extra things to try outside of what is covered on this page. You can find the checklist [here](performance_checklist.md).
diff --git a/examples/large_models/Huggingface_accelerate/llama2/Readme.md b/examples/large_models/Huggingface_accelerate/llama2/Readme.md
new file mode 100644
index 0000000000..8151b4a941
--- /dev/null
+++ b/examples/large_models/Huggingface_accelerate/llama2/Readme.md
@@ -0,0 +1,60 @@
+# Loading meta-llama/Llama-2-70b-chat-hf on AWS EC2 g5.24xlarge using accelerate
+
+This document briefs on serving large HG models with limited resource using accelerate. This option can be activated with `low_cpu_mem_usage=True`. The model is first created on the Meta device (with empty weights) and the state dict is then loaded inside it (shard by shard in the case of a sharded checkpoint).
+
+### Step 1: Download model Permission
+
+Follow [this instruction](https://huggingface.co/meta-llama/Llama-2-70b-chat-hf) to get permission
+
+Login with a Hugging Face account
+```
+huggingface-cli login
+# or using an environment variable
+huggingface-cli login --token $HUGGINGFACE_TOKEN
+```
+
+```bash
+python ../Download_model.py --model_path model --model_name meta-llama/Llama-2-70b-chat-hf
+```
+Model will be saved in the following path, `model/models--meta-llama--Llama-2-70b-chat-hf`.
+
+### Step 2: Generate MAR file
+
+Add the downloaded path to " model_path:" in `model-config.yaml` and run the following.
+
+```bash
+torch-model-archiver --model-name llama2-70b-chat --version 1.0 --handler custom_handler.py --config-file model-config.yaml -r requirements.txt --archive-format no-archive
+```
+
+If you are using conda, and notice issues with mpi4py, you would need to install openmpi-mpicc using the following
+
+```
+conda install -c conda-forge openmpi-mpicc
+```
+
+### Step 3: Add the mar file to model store
+
+```bash
+mkdir model_store
+mv llama2-70b-chat model_store
+mv model model_store/llama2-70b-chat
+```
+
+### Step 3: Start torchserve
+
+Update config.properties and start torchserve
+
+```bash
+torchserve --start --ncs --ts-config config.properties --model-store model_store --models llama2-70b-chat
+```
+
+### Step 4: Run inference
+
+```bash
+curl -v "http://localhost:8080/predictions/llama2-70b-chat" -T sample_text.txt
+```
+
+results in the following output
+```
+Mayonnaise is a thick, creamy condiment made from a mixture of egg yolks, oil, vinegar or lemon juice, and seasonings'
+```
diff --git a/examples/large_models/Huggingface_accelerate/llama2/config.properties b/examples/large_models/Huggingface_accelerate/llama2/config.properties
new file mode 100644
index 0000000000..eadd0140da
--- /dev/null
+++ b/examples/large_models/Huggingface_accelerate/llama2/config.properties
@@ -0,0 +1,6 @@
+inference_address=http://0.0.0.0:8080
+management_address=http://0.0.0.0:8081
+metrics_address=http://0.0.0.0:8082
+enable_envvars_config=true
+install_py_dep_per_model=true
+
diff --git a/examples/large_models/Huggingface_accelerate/llama2/custom_handler.py b/examples/large_models/Huggingface_accelerate/llama2/custom_handler.py
new file mode 100644
index 0000000000..5ad376894e
--- /dev/null
+++ b/examples/large_models/Huggingface_accelerate/llama2/custom_handler.py
@@ -0,0 +1,139 @@
+import logging
+from abc import ABC
+
+import torch
+import transformers
+from transformers import AutoConfig, AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
+from accelerate import init_empty_weights
+from accelerate import load_checkpoint_and_dispatch
+
+from ts.context import Context
+from ts.torch_handler.base_handler import BaseHandler
+
+logger = logging.getLogger(__name__)
+logger.info("Transformers version %s", transformers.__version__)
+
+
+class LlamaHandler(BaseHandler, ABC):
+ """
+ Transformers handler class for sequence, token classification and question answering.
+ """
+
+ def __init__(self):
+ super(LlamaHandler, self).__init__()
+ self.max_length = None
+ self.max_new_tokens = None
+ self.tokenizer = None
+ self.initialized = False
+
+ def initialize(self, ctx: Context):
+ """In this initialize function, the HF large model is loaded and
+ partitioned using DeepSpeed.
+ Args:
+ ctx (context): It is a JSON Object containing information
+ pertaining to the model artifacts parameters.
+ """
+ model_dir = ctx.system_properties.get("model_dir")
+ self.max_length = int(ctx.model_yaml_config["handler"]["max_length"])
+ self.max_new_tokens = int(ctx.model_yaml_config["handler"]["max_new_tokens"])
+ model_name = ctx.model_yaml_config["handler"]["model_name"]
+ model_path = f'{model_dir}/{ctx.model_yaml_config["handler"]["model_path"]}'
+ seed = int(ctx.model_yaml_config["handler"]["manual_seed"])
+ torch.manual_seed(seed)
+
+ logger.info("Model %s loading tokenizer", ctx.model_name)
+ self.model = AutoModelForCausalLM.from_pretrained(
+ model_path,
+ device_map="balanced",
+ low_cpu_mem_usage=True,
+ torch_dtype=torch.float16,
+ load_in_8bit=True,
+ trust_remote_code=True)
+ self.tokenizer = AutoTokenizer.from_pretrained(model_name)
+ self.tokenizer.add_special_tokens(
+ {
+
+ "pad_token": "",
+ }
+ )
+ self.model.resize_token_embeddings(self.model.config.vocab_size + 1)
+
+ logger.info("Model %s loaded successfully", ctx.model_name)
+ self.initialized = True
+
+ def preprocess(self, requests):
+ """
+ Basic text preprocessing, based on the user's choice of application mode.
+ Args:
+ requests (list): A list of dictionaries with a "data" or "body" field, each
+ containing the input text to be processed.
+ Returns:
+ tuple: A tuple with two tensors: the batch of input ids and the batch of
+ attention masks.
+ """
+ input_texts = [data.get("data") or data.get("body") for data in requests]
+ input_ids_batch, attention_mask_batch = [], []
+ for input_text in input_texts:
+ input_ids, attention_mask = self.encode_input_text(input_text)
+ input_ids_batch.append(input_ids)
+ attention_mask_batch.append(attention_mask)
+ input_ids_batch = torch.cat(input_ids_batch, dim=0).to(self.model.device)
+ attention_mask_batch = torch.cat(attention_mask_batch, dim=0).to(self.device)
+ return input_ids_batch, attention_mask_batch
+
+ def encode_input_text(self, input_text):
+ """
+ Encodes a single input text using the tokenizer.
+ Args:
+ input_text (str): The input text to be encoded.
+ Returns:
+ tuple: A tuple with two tensors: the encoded input ids and the attention mask.
+ """
+ if isinstance(input_text, (bytes, bytearray)):
+ input_text = input_text.decode("utf-8")
+ logger.info("Received text: '%s'", input_text)
+ inputs = self.tokenizer.encode_plus(
+ input_text,
+ max_length=self.max_length,
+ padding=True,
+ add_special_tokens=True,
+ return_tensors="pt",
+ truncation=True,
+ )
+ input_ids = inputs["input_ids"]
+ attention_mask = inputs["attention_mask"]
+ return input_ids, attention_mask
+
+ def inference(self, input_batch):
+ """
+ Predicts the class (or classes) of the received text using the serialized transformers
+ checkpoint.
+ Args:
+ input_batch (tuple): A tuple with two tensors: the batch of input ids and the batch
+ of attention masks, as returned by the preprocess function.
+ Returns:
+ list: A list of strings with the predicted values for each input text in the batch.
+ """
+ input_ids_batch, attention_mask_batch = input_batch
+ input_ids_batch = input_ids_batch.to(self.device)
+ outputs = self.model.generate(
+ input_ids_batch,
+ attention_mask=attention_mask_batch,
+ max_length=self.max_new_tokens,
+ )
+
+ inferences = self.tokenizer.batch_decode(
+ outputs, skip_special_tokens=True, clean_up_tokenization_spaces=False
+ )
+
+ logger.info("Generated text: %s", inferences)
+ return inferences
+
+ def postprocess(self, inference_output):
+ """Post Process Function converts the predicted response into Torchserve readable format.
+ Args:
+ inference_output (list): It contains the predicted response of the input text.
+ Returns:
+ (list): Returns a list of the Predictions and Explanations.
+ """
+ return inference_output
diff --git a/examples/large_models/Huggingface_accelerate/llama2/model-config.yaml b/examples/large_models/Huggingface_accelerate/llama2/model-config.yaml
new file mode 100644
index 0000000000..66e020b52d
--- /dev/null
+++ b/examples/large_models/Huggingface_accelerate/llama2/model-config.yaml
@@ -0,0 +1,13 @@
+# TorchServe frontend parameters
+minWorkers: 1
+maxWorkers: 1
+maxBatchDelay: 100
+responseTimeout: 1200
+deviceType: "gpu"
+
+handler:
+ model_name: "meta-llama/Llama-2-70b-chat-hf"
+ model_path: "model/models--meta-llama--Llama-2-70b-chat-hf/snapshots/9ff8b00464fc439a64bb374769dec3dd627be1c2"
+ max_length: 50
+ max_new_tokens: 50
+ manual_seed: 40
diff --git a/examples/large_models/Huggingface_accelerate/llama2/requirements.txt b/examples/large_models/Huggingface_accelerate/llama2/requirements.txt
new file mode 100644
index 0000000000..0daea4cee1
--- /dev/null
+++ b/examples/large_models/Huggingface_accelerate/llama2/requirements.txt
@@ -0,0 +1,5 @@
+transformers==4.31.0
+accelerate
+bitsandbytes
+scipy
+mpi4py
diff --git a/examples/large_models/Huggingface_accelerate/llama2/sample_text.txt b/examples/large_models/Huggingface_accelerate/llama2/sample_text.txt
new file mode 100644
index 0000000000..edfe9f4c10
--- /dev/null
+++ b/examples/large_models/Huggingface_accelerate/llama2/sample_text.txt
@@ -0,0 +1 @@
+what is the recipe of mayonnaise?
\ No newline at end of file
diff --git a/examples/object_detector/yolo/yolov8/README.md b/examples/object_detector/yolo/yolov8/README.md
new file mode 100644
index 0000000000..dcfe975c9c
--- /dev/null
+++ b/examples/object_detector/yolo/yolov8/README.md
@@ -0,0 +1,64 @@
+# Object Detection using Ultralytics's pretrained YOLOv8(yolov8n) model.
+
+
+Install `ultralytics` using
+```
+python -m pip install -r requirements.txt
+```
+
+In this example, we are using the YOLOv8 Nano model from ultralytics.Downlaod the pretrained weights from [Ultralytics](https://docs.ultralytics.com/models/yolov8/#supported-modes)
+
+```
+wget https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n.pt
+```
+
+We need a custom handler to load the YOLOv8n model. The default `initialize` function loads `.pt` file using `torch.jit.load`. This doesn't work for YOLOv8n model. Hence, we need a custom handler with an `initialize` method where we load the model using ultralytics.
+
+## Create a model archive file for Yolov8n model
+
+```
+torch-model-archiver --model-name yolov8n --version 1.0 --serialized-file yolov8n.pt --handler custom_handler.py
+```
+
+```
+mkdir model_store
+mv yolov8n.mar model_store/.
+```
+
+## Start TorchServe and register the model
+
+
+```
+torchserve --start --model-store model_store --ncs
+curl -X POST "localhost:8081/models?model_name=yolov8n&url=yolov8n.mar&initial_workers=4&batch_size=2"
+```
+
+results in
+
+```
+{
+ "status": "Model \"yolov8n\" Version: 1.0 registered with 4 initial workers"
+}
+```
+
+## Run Inference
+
+Here we are counting the number of detected objects in the image. You can change the post-process method in the handler to return the bounding box coordinates
+
+```
+curl http://127.0.0.1:8080/predictions/yolov8n -T persons.jpg & curl http://127.0.0.1:8080/predictions/yolov8n -T bus.jpg
+```
+
+gives the output
+
+```
+{
+ "person": 4,
+ "handbag": 3,
+ "bench": 3
+}{
+ "person": 4,
+ "bus": 1,
+ "stop sign": 1
+}
+```
diff --git a/examples/object_detector/yolo/yolov8/bus.jpg b/examples/object_detector/yolo/yolov8/bus.jpg
new file mode 100644
index 0000000000..b43e311165
Binary files /dev/null and b/examples/object_detector/yolo/yolov8/bus.jpg differ
diff --git a/examples/object_detector/yolo/yolov8/custom_handler.py b/examples/object_detector/yolo/yolov8/custom_handler.py
new file mode 100644
index 0000000000..c91779c079
--- /dev/null
+++ b/examples/object_detector/yolo/yolov8/custom_handler.py
@@ -0,0 +1,79 @@
+import logging
+import os
+from collections import Counter
+
+import torch
+from torchvision import transforms
+from ultralytics import YOLO
+
+from ts.torch_handler.object_detector import ObjectDetector
+
+logger = logging.getLogger(__name__)
+
+try:
+ import torch_xla.core.xla_model as xm
+
+ XLA_AVAILABLE = True
+except ImportError as error:
+ XLA_AVAILABLE = False
+
+
+class Yolov8Handler(ObjectDetector):
+ image_processing = transforms.Compose(
+ [transforms.Resize(640), transforms.CenterCrop(640), transforms.ToTensor()]
+ )
+
+ def __init__(self):
+ super(Yolov8Handler, self).__init__()
+
+ def initialize(self, context):
+ # Set device type
+ if torch.cuda.is_available():
+ self.device = torch.device("cuda")
+ elif XLA_AVAILABLE:
+ self.device = xm.xla_device()
+ else:
+ self.device = torch.device("cpu")
+
+ # Load the model
+ properties = context.system_properties
+ self.manifest = context.manifest
+ model_dir = properties.get("model_dir")
+ self.model_pt_path = None
+ if "serializedFile" in self.manifest["model"]:
+ serialized_file = self.manifest["model"]["serializedFile"]
+ self.model_pt_path = os.path.join(model_dir, serialized_file)
+ self.model = self._load_torchscript_model(self.model_pt_path)
+ logger.debug("Model file %s loaded successfully", self.model_pt_path)
+
+ self.initialized = True
+
+ def _load_torchscript_model(self, model_pt_path):
+ """Loads the PyTorch model and returns the NN model object.
+
+ Args:
+ model_pt_path (str): denotes the path of the model file.
+
+ Returns:
+ (NN Model Object) : Loads the model object.
+ """
+ # TODO: remove this method if https://github.com/pytorch/text/issues/1793 gets resolved
+
+ model = YOLO(model_pt_path)
+ model.to(self.device)
+ return model
+
+ def postprocess(self, res):
+ output = []
+ for data in res:
+ classes = data.boxes.cls.tolist()
+ names = data.names
+
+ # Map to class names
+ classes = map(lambda cls: names[int(cls)], classes)
+
+ # Get a count of objects detected
+ result = Counter(classes)
+ output.append(dict(result))
+
+ return output
diff --git a/examples/object_detector/yolo/yolov8/persons.jpg b/examples/object_detector/yolo/yolov8/persons.jpg
new file mode 100644
index 0000000000..861d56a033
Binary files /dev/null and b/examples/object_detector/yolo/yolov8/persons.jpg differ
diff --git a/examples/object_detector/yolo/yolov8/requirements.txt b/examples/object_detector/yolo/yolov8/requirements.txt
new file mode 100644
index 0000000000..c5db96688c
--- /dev/null
+++ b/examples/object_detector/yolo/yolov8/requirements.txt
@@ -0,0 +1 @@
+ultralytics>=8.0.144
diff --git a/kubernetes/AKS/README.md b/kubernetes/AKS/README.md
index 4948e10f14..99b6074fe4 100644
--- a/kubernetes/AKS/README.md
+++ b/kubernetes/AKS/README.md
@@ -291,7 +291,7 @@ az group delete --name myResourceGroup --yes --no-wait
```
## Troubleshooting
-
+
**Troubleshooting Azure Cli login**
@@ -299,11 +299,11 @@ az group delete --name myResourceGroup --yes --no-wait
Otherwise, open a browser page at https://aka.ms/devicelogin and enter the authorization code displayed in your terminal.
If no web browser is available or the web browser fails to open, use device code flow with az login --use-device-code.
Or you can login with your credential in command line, more details, see https://docs.microsoft.com/en-us/cli/azure/authenticate-azure-cli.
-
+
**Troubleshooting Azure resource for AKS cluster creation**
-
- * Check AKS available region, https://azure.microsoft.com/en-us/explore/global-infrastructure/products-by-region/?products=kubernetes-service
+
+ * Check AKS available region, https://azure.microsoft.com/en-us/explore/global-infrastructure/products-by-region/
* Check AKS quota and VM size limitation, https://docs.microsoft.com/en-us/azure/aks/quotas-skus-regions
* Check whether your subscription has enough quota to create AKS cluster, https://docs.microsoft.com/en-us/azure/networking/check-usage-against-limits
-
+
**For more AKS troubleshooting, please visit https://docs.microsoft.com/en-us/azure/aks/troubleshooting**
diff --git a/ts/torch_handler/base_handler.py b/ts/torch_handler/base_handler.py
index 227a4ec56c..4b763a9e97 100644
--- a/ts/torch_handler/base_handler.py
+++ b/ts/torch_handler/base_handler.py
@@ -198,7 +198,7 @@ def initialize(self, context):
backend=pt2_backend,
)
logger.info(f"Compiled model with backend {pt2_backend}")
- except e:
+ except Exception as e:
logger.warning(
f"Compiling model model with backend {pt2_backend} has failed \n Proceeding without compilation"
)
diff --git a/ts_scripts/spellcheck_conf/wordlist.txt b/ts_scripts/spellcheck_conf/wordlist.txt
index 9f6e6e8aab..9aa7a9223f 100644
--- a/ts_scripts/spellcheck_conf/wordlist.txt
+++ b/ts_scripts/spellcheck_conf/wordlist.txt
@@ -1071,6 +1071,19 @@ meshConfig
baseimage
cuDNN
Xformer
+MiniLM
+SIMD
+SLA
+htop
+jpeg
+libjpeg
+lightseq
+multithreading
+onnxruntime
+pipelining
+tensorRT
+utilizations
+ctranslate
grpcurl
ExamplePercentMetric
HandlerMethodTime