Protecting privacy and confidentiality is critical for large-scale data analysis, AI, and increasingly important LLM applications. BigDL PPML (Privacy Preserving Machine Learning) combines various low-level hardware and software security technologies (e.g., Intel® SGX, Intel® TDX, Security Key Management, Remote Attestation, Data Encryption, etc.) so that users can continue applying standard Big Data, AI and LLM technologies (such as Apache Spark, Apache Flink, TensorFlow, PyTorch, BigDL-LLM etc.) without sacrificing privacy.
- 1. What is BigDL PPML?
- 2. Why BigDL PPML?
- 3. Getting Started with PPML
- 4. Develop your own Big Data & AI applications with BigDL PPML
ppml.intro.mp4
Protecting data privacy and confidentiality is critical in a world where data is everywhere. In recent years, more and more countries have enacted data privacy legislation or are expected to pass comprehensive legislation to protect data privacy, the importance of privacy and data protection is increasingly recognized.
To better protect sensitive data, it's necessary to ensure security for all dimensions of data lifecycle: data at rest, data in transit, and data in use. Data being transferred on a network is in transit, data in storage is at rest, and data being processed is in use.

To protect data in transit, enterprises often choose to encrypt sensitive data prior to moving or use encrypted connections (HTTPS, SSL, TLS, FTPS, etc) to protect the contents of data in transit. For protecting data at rest, enterprises can simply encrypt sensitive files prior to storing them or choose to encrypt the storage drive itself. However, the third state, data in use has always been a weakly protected target. There are three emerging solutions that seek to reduce the data-in-use attack surface: homomorphic encryption, multi-party computation, and confidential computing.
Among these security technologies, Confidential computing protects data in use by performing computation in a hardware-based Trusted Execution Environment (TEE). Intel® SGX is Intel's Trusted Execution Environment (TEE), offering hardware-based memory encryption that isolates specific application code and data in memory. Intel® TDX is the next generation of Intel's Trusted Execution Environment (TEE), introducing new, architectural elements to help deploy hardware-isolated, virtual machines (VMs) called trust domains (TDs).
PPML (Privacy Preserving Machine Learning) in BigDL 2.0 provides a Trusted Cluster Environment for secure Big Data & AI applications, even on untrusted cloud environment. By combining Intel Software Guard Extensions (SGX) with several other security technologies (e.g., attestation, key management service, private set intersection, federated learning, homomorphic encryption, etc.), BigDL PPML ensures end-to-end security enabled for the entire distributed workflows, such as Apache Spark, Apache Flink, XGBoost, TensorFlow, PyTorch, etc.
PPML allows organizations to explore powerful AI techniques while working to minimize the security risks associated with handling large amounts of sensitive data. PPML protects data at rest, in transit and in use: compute and memory protected by SGX Enclaves, TDX VMs, TDX Confidential Containers, storage (e.g., data and model) protected by encryption, network communication protected by remote attestation and Transport Layer Security (TLS).

With BigDL PPML, you can run trusted Big Data & AI applications
- Trusted Spark SQL & Dataframe: with trusted Big Data analytics support, users can run standard Spark data analysis (such as Spark SQL, Dataframe, MLlib, etc.) in a secure and trusted fashion.
- Trusted ML (Machine Learning): with trusted Big Data analytics and ML support, users can run distributed machine learning (such as MLlib, LightGBM) in a secure and trusted fashion.
- Trusted DL (Deep Learning): with trusted Big Data analytics and DL support, users can run distributed deep learning (such as BigDL, Orca, Nano, and PyTorch, Tensorflow) in a secure and trusted fashion.
- Trusted DL Serving: with trusted DL Serving support, users can run distributed DL serving (such as TorchServe, TF Serving, etc.) in a secure and trusted fashion.
- Trusted LLM (Large Language Model): with trusted LLM support, users can run distributed LLM serving and fine-tuning with BigDL-LLM in a secure and trusted fashion.
In this section, you can get started with running a simple native python HelloWorld program and a simple native Spark Pi program locally in a BigDL PPML local docker container to get an initial understanding of the usage of ppml.
Click to see detailed steps
a. Prepare Images
For demo purposes, we will skip building the custom image here and use the public reference image provided by BigDL PPML intelanalytics/bigdl-ppml-trusted-bigdata-gramine-reference-8g:2.5.0-SNAPSHOT to have a quick start.
Note: This public image is only for demo purposes, it is non-production. For security concerns, you are strongly recommended to generate your enclave key and build your custom image for your production environment. Refer to How to Prepare Your PPML image for production environment.
b. Prepare Keys
-
generate ssl_key
Download scripts from here.
cd BigDL/ppml/ sudo bash scripts/generate-keys.shThis script will generate keys under keys/ folder
c. Start the BigDL PPML Local Container
# KEYS_PATH means the absolute path to the keys folder in step a
# LOCAL_IP means your local IP address.
export KEYS_PATH=YOUR_LOCAL_KEYS_PATH
export LOCAL_IP=YOUR_LOCAL_IP
# ppml graphene image is deprecated, please use the gramine version
export DOCKER_IMAGE=intelanalytics/bigdl-ppml-trusted-big-data-ml-python-gramine-reference:2.5.0-SNAPSHOT
sudo docker pull $DOCKER_IMAGE
sudo docker run -itd \
--net=host \
--cpus=5 \
--oom-kill-disable \
--device=/dev/gsgx \
--device=/dev/sgx/enclave \
--device=/dev/sgx/provision \
--name=bigdl-ppml-client-local \
-v /var/run/aesmd/aesm.socket:/var/run/aesmd/aesm.socket \
-v $KEYS_PATH:/ppml/keys \
-e RUNTIME_DRIVER_PORT=54321 \
-e RUNTIME_DRIVER_MEMORY=1g \
-e LOCAL_IP=$LOCAL_IP \
$DOCKER_IMAGE bash
d. Run Python HelloWorld in BigDL PPML Local Container
Run the script to run trusted Python HelloWorld in BigDL PPML client container:
sudo docker exec -it bigdl-ppml-client-local bash work/scripts/start-python-helloword-on-sgx.sh
Check the log:
sudo docker exec -it bigdl-ppml-client-local cat /ppml/test-helloworld-sgx.log | egrep "Hello World"
The result should look something like this:
Hello World
e. Run Spark Pi in BigDL PPML Local Container
Run the script to run trusted Spark Pi in BigDL PPML client container:
sudo docker exec -it bigdl-ppml-client-local bash work/scripts/start-spark-pi-on-local-sgx.shCheck the log:
sudo docker exec -it bigdl-ppml-client-local cat /ppml/test-pi-sgx.log | egrep "roughly"The result should look something like this:
Pi is roughly 3.146760
 In this section, we take SimpleQuery as an example to go through the entire BigDL PPML end-to-end workflow. SimpleQuery is a simple example to query developers between the ages of 20 and 40 from people.csv.
In this section, we take SimpleQuery as an example to go through the entire BigDL PPML end-to-end workflow. SimpleQuery is a simple example to query developers between the ages of 20 and 40 from people.csv.
ppml.e2e.workflow.mp4
To secure your Big Data & AI applications in BigDL PPML manner, you should prepare your environment first, including K8s cluster setup, K8s-SGX plugin setup, key/password preparation, key management service (KMS) and attestation service (AS) setup, BigDL PPML client container preparation. Please follow the detailed steps in Prepare Environment.
Next, you are going to build a base image, and a custom image on top of it to avoid leaving secrets e.g. enclave key in images/containers. After that, you need to register the mrenclave in your custom image to Attestation Service Before running your application, and PPML will verify the runtime MREnclave automatically at the backend. The below chart illustrated the whole workflow:

Start your application with the following guide step by step:
To build a secure PPML image that can be used in a production environment, BigDL prepared a public base image that does not contain any secrets. You can customize your image on top of this base image.
-
Prepare BigDL Base Image
The bigdata base image is a public one that does not contain any secrets. You will use the base image to get your own custom image in the following.
You can use our public bigdata base image
intelanalytics/bigdl-ppml-trusted-bigdata-gramine-base:2.5.0-SNAPSHOT, which is recommended. Or you can build your own base image, which is expected to be exactly the same as ours.Before building your own base image, please modify the paths in
ppml/trusted-bigdata/build-base-image.sh. Then build the docker image with the following command../build-bigdata-base-image.sh
-
Build Custom Image
When the base image is ready, you need to generate your enclave key which will be used when building a custom image and keep the enclave key safe for future remote attestations.
Running the following command to generate the enclave key
enclave-key.pem, which is used to launch and sign SGX Enclave.cd custom-image openssl genrsa -3 -out enclave-key.pem 3072When the enclave key
enclave-key.pemis generated, you are ready to build your custom image by running the following command:# under bigdl-gramine dir # modify custom parameters in build-custom-image.sh ./build-custom-image.sh cd ..
Warning: If you want to skip DCAP attestation in runtime containers, you can set
ENABLE_DCAP_ATTESTATIONto false inbuild-custom-image.sh, and this will generate a none-attestation image. But never do this unsafe operation in production!The sensitive enclave key will not be saved in the built image. Two values
mr_enclaveandmr_signerare recorded while the Enclave is built, you can findmr_enclaveandmr_signervalues in the console log, which are hash values used to register your MREnclave in the following attestation step.
Attributes: mr_enclave: 56ba...... mr_signer: 422c...... ````
Note: you can also customize the image according to your own needs, e.g. install an extra python library, add code, or jars.
Then, start a client container:
```
export K8S_MASTER=k8s://$(sudo kubectl cluster-info | grep 'https.*6443' -o -m 1)
echo The k8s master is $K8S_MASTER .
export DATA_PATH=/YOUR_DIR/data
export KEYS_PATH=/YOUR_DIR/keys
export SECURE_PASSWORD_PATH=/YOUR_DIR/password
export KUBECONFIG_PATH=/YOUR_DIR/config
export LOCAL_IP=$LOCAL_IP
export DOCKER_IMAGE=intelanalytics/bigdl-ppml-trusted-bigdata-gramine-reference-8g:2.5.0-SNAPSHOT # or the custom image built by yourself
sudo docker run -itd \
--net=host \
--name=bigdl-ppml-client-k8s \
--cpus=10 \
--oom-kill-disable \
--device=/dev/sgx/enclave \
--device=/dev/sgx/provision \
-v /var/run/aesmd/aesm.socket:/var/run/aesmd/aesm.socket \
-v $DATA_PATH:/ppml/data \
-v $KEYS_PATH:/ppml/keys \
-v $SECURE_PASSWORD_PATH:/ppml/password \
-v $KUBECONFIG_PATH:/root/.kube/config \
-e RUNTIME_SPARK_MASTER=$K8S_MASTER \
-e RUNTIME_DRIVER_HOST=$LOCAL_IP \
-e RUNTIME_K8S_SPARK_IMAGE=$DOCKER_IMAGE \
-e RUNTIME_DRIVER_PORT=54321 \
-e RUNTIME_DRIVER_MEMORY=1g \
-e LOCAL_IP=$LOCAL_IP \
$DOCKER_IMAGE bash
```
Enter the client container:
sudo docker exec -it bigdl-ppml-client-k8s bash
If you do not need the attestation, you can disable the attestation service. You should configure spark-driver-template.yaml and spark-executor-template in the client container.yaml to set ATTESTATION value to false and skip the rest of the step. By default, the attestation service is disabled.
apiVersion: v1
kind: Pod
spec:
...
env:
- name: ATTESTATION
value: false
...The bi-attestation guarantees that the MREnclave in runtime containers is a secure one made by you. Its workflow is as below:

To enable attestation, you should have a running Attestation Service in your environment.
1. Deploy EHSM KMS & AS
KMS (Key Management Service) and AS (Attestation Service) make sure applications of the customer run in the SGX MREnclave signed above by customer-self, rather than a fake one fake by an attacker.
BigDL PPML uses EHSM as a reference KMS & AS, you can follow the guide here to deploy EHSM in your environment.
2. Enroll in EHSM
Execute the following command to enroll yourself in EHSM, The <kms_ip> is your configured-ip of EHSM service in the deployment section:
curl -v -k -G "https://<kms_ip>:9000/ehsm?Action=Enroll"
......
{"code":200,"message":"successful","result":{"apikey":"E8QKpBB******","appid":"8d5dd3b*******"}}You will get an appid and apikey pair. Please save it for later use.
3. Attest EHSM Server (optional)
You can attest EHSM server and verify the service is trusted before running workloads to avoid sending your secrets to a fake service.
To attest EHSM server, start a BigDL container using the custom image built before. Note: this is the other container different from the client.
export KEYS_PATH=YOUR_LOCAL_SPARK_SSL_KEYS_FOLDER_PATH
export LOCAL_IP=YOUR_LOCAL_IP
export CUSTOM_IMAGE=YOUR_CUSTOM_IMAGE_BUILT_BEFORE
export PCCS_URL=YOUR_PCCS_URL # format like https://1.2.3.4:xxxx, obtained from KMS services or a self-deployed one
sudo docker run -itd \
--net=host \
--cpus=5 \
--oom-kill-disable \
-v /var/run/aesmd/aesm.socket:/var/run/aesmd/aesm.socket \
-v $KEYS_PATH:/ppml/trusted-big-data-ml/work/keys \
--name=gramine-verify-worker \
-e LOCAL_IP=$LOCAL_IP \
-e PCCS_URL=$PCCS_URL \
$CUSTOM_IMAGE bashEnter the docker container:
sudo docker exec -it gramine-verify-worker bashSet the variables in verify-attestation-service.sh before running it:
`ATTESTATION_URL`: URL of attestation service. Should match the format `<ip_address>:<port>`.
`APP_ID`, `API_KEY`: The appID and apiKey pair generated by your attestation service.
`ATTESTATION_TYPE`: Type of attestation service. Currently support `EHSMAttestationService`.
`CHALLENGE`: Challenge to get a quote for attestation service which will be verified by local SGX SDK. Should be a BASE64 string. It can be a casual BASE64 string, for example, it can be generated by the command `echo anystring|base64`.
In the container, execute verify-attestation-service.sh to verify the attestation service quote.
bash verify-attestation-service.sh4. Register your MREnclave to EHSM
Register the MREnclave with metadata of your MREnclave (appid, apikey, mr_enclave, mr_signer) obtained in above steps to EHSM through running a python script:
# At /ppml/trusted-big-data-ml inside the container now
python register-mrenclave.py --appid <your_appid> \
--apikey <your_apikey> \
--url https://<kms_ip>:9000 \
--mr_enclave <your_mrenclave_hash_value> \
--mr_signer <your_mrensigner_hash_value>You will receive a response containing a policyID and save it which will be used to attest runtime MREnclave when running distributed kubernetes application.
5. Enable Attestation in configuration
First, upload appid, apikey and policyID obtained before to kubernetes as secrets:
kubectl create secret generic kms-secret \
--from-literal=app_id=YOUR_KMS_APP_ID \
--from-literal=api_key=YOUR_KMS_API_KEY \
--from-literal=policy_id=YOUR_POLICY_IDConfigure spark-driver-template.yaml and spark-executor-template.yaml to enable Attestation as follows:
apiVersion: v1
kind: Pod
spec:
containers:
- name: spark-driver
env:
- name: ATTESTATION
value: true
- name: PCCS_URL
value: https://your_pccs_ip:your_pccs_port
- name: ATTESTATION_URL
value: your_attestation_url
- name: APP_ID
valueFrom:
secretKeyRef:
name: kms-secret
key: app_id
- name: API_KEY
valueFrom:
secretKeyRef:
name: kms-secret
key: app_key
- name: ATTESTATION_POLICYID
valueFrom:
secretKeyRef:
name: policy-id-secret
key: policy_id
...You should get Attestation Success! in logs after you submit a PPML job if the quote generated with user_report is verified successfully by Attestation Service. Or you will get Attestation Fail! Application killed! or JASONObject["result"] is not a JASONObjectand the job will be stopped.
Encrypt the input data of your Big Data & AI applications (here we use SimpleQuery) and then upload encrypted data to the nfs server (or any file system such as HDFS that can be accessed by the cluster).
-
Generate the input data
people.csvfor SimpleQuery application you can use generate_people_csv.py. The usage command of the script ispython generate_people.py </save/path/of/people.csv> <num_lines>. The save path should be reachable bypeople.csv, like a shared docker-mount-path. -
Generate a primary key.
docker exec -i bigdl-ppml-client-k8s bash cd /ppml/bigdl-ppml/src/bigdl/ppml/kms/ehsm/ export APIKEY=your_apikey export APPID=your_appid python client.py -api generate_primary_key -ip ehsm_ip -port ehsm_port -
Encrypt
people.csvAs for data encryption/decryption based on crypto, We recommend you to use data key generated from primary key, which are both managed by KMS(Key Management Service) that is not only convenient but also safe. This is contributed by that our KMSs like EHSM have hardware-protected memory and TLS/SSL-encrypted network etc. and no sensitive secret is written to disk.
In practice, you only need to specify a KMS-pre-generated primary key when submitting job, and PPMLContext backend will automatically generate a data key from the primary one you provide, and manage the two in the whole lifecycle:
Method 1: Encrypt with KMS-Managed Primary and Data Keys
docker exec -i bigdl-ppml-client-k8s bash bash bigdl-ppml-submit.sh \ --master local[2] \ --sgx-enabled false \ --driver-memory 5g \ --driver-cores 4 \ --executor-memory 5g \ --executor-cores 4 \ --num-executors 2 \ --conf spark.cores.max=8 \ --conf spark.network.timeout=10000000 \ --conf spark.executor.heartbeatInterval=10000000 \ --conf spark.hadoop.io.compression.codecs="com.intel.analytics.bigdl.ppml.crypto.CryptoCodec" \ --conf spark.bigdl.primaryKey.amy.kms.type=EHSMKeyManagementService \ --conf spark.bigdl.primaryKey.amy.material=path_to/your_primary_key \ --conf spark.bigdl.primaryKey.amy.kms.ip=your_kms_ip \ --conf spark.bigdl.primaryKey.amy.kms.port=your_kms_port \ --conf spark.bigdl.primaryKey.amy.kms.appId=your_kms_appId \ --conf spark.bigdl.primaryKey.amy.kms.apiKey=your_kms_apiKey\ --verbose \ --class com.intel.analytics.bigdl.ppml.utils.Encrypt \ --conf spark.executor.extraClassPath=$BIGDL_HOME/jars/* \ --conf spark.driver.extraClassPath=$BIGDL_HOME/jars/* \ --name amy-encrypt \ local://$BIGDL_HOME/jars/bigdl-ppml-spark_$SPARK_VERSION-$BIGDL_VERSION.jar \ --inputDataSourcePath file://</save/path/of/people.csv> \ --outputDataSinkPath file://</output/path/to/save/encrypted/people.csv> \ --cryptoMode aes/cbc/pkcs5padding \ --dataSourceType csv \ --action encrypt
As there may be a scenario where KMS cannot be accessed, you are allowed to directly provide a primary key in plain text instead of requesting from the service. Note: Do not use this in production in consider of security:
Method 2: Encrypt with Self-Provided Primary Key in Plain Text
docker exec -i bigdl-ppml-client-k8s bash export PLAIN_TEXT_DATA_KEY=your_self_provided_128_bit_base_64_string bash bigdl-ppml-submit.sh \ --master local[2] \ --sgx-enabled false \ --driver-memory 32g \ --driver-cores 4 \ --executor-memory 32g \ --executor-cores 4 \ --num-executors 2 \ --conf spark.cores.max=8 \ --conf spark.network.timeout=10000000 \ --conf spark.executor.heartbeatInterval=10000000 \ --conf spark.hadoop.io.compression.codecs="com.intel.analytics.bigdl.ppml.crypto.CryptoCodec" \ --conf spark.bigdl.primaryKey.dataSource1PK.plainText=${PLAIN_TEXT_DATA_KEY} \ --verbose \ --class com.intel.analytics.bigdl.ppml.utils.Encrypt \ --jars local://$SPARK_HOME/examples/jars/scopt_2.12-3.7.1.jar,local://$BIGDL_HOME/jars/bigdl-dllib-spark_3.1.2-2.1.0-SNAPSHOT.jar \ local://$BIGDL_HOME/jars/bigdl-ppml-spark_3.1.2-2.1.0-SNAPSHOT.jar \ --inputDataSourcePath file://</save/path/of/people.csv> \ --outputDataSinkPath file://</output/path/to/save/encrypted/people.csv> \ --cryptoMode aes/cbc/pkcs5padding \ --dataSourceType csv \ --action encrypt
Amyis free to set, as long as it is consistent in the parameters. Do this step twice to encrypt amy.csv and bob.csv. If the application works successfully, you will see the encrypted files inoutputDataSinkPath.
To build your own Big Data & AI applications, refer to develop your own Big Data & AI applications with BigDL PPML. The code of SimpleQuery is in here, it is already built into bigdl-ppml-spark_${SPARK_VERSION}-${BIGDL_VERSION}.jar, and the jar is put into PPML image.
When the Big Data & AI application and its input data is prepared, you are ready to submit BigDL PPML jobs.
You need to choose the deploy mode and the way to submit the job first.
-
There are 4 modes to submit a job:
-
local mode: run jobs locally without connecting to the cluster. It is exactly the same as using spark-submit to run your application:
$SPARK_HOME/bin/spark-submit --class "SimpleApp" --master local[4] target.jar, driver and executors are not protected by SGX.
-
local SGX mode: run jobs locally with SGX guarded. As the picture shows, the client JVM is running in a SGX Enclave so that driver and executors can be protected.

-
client SGX mode: run jobs in k8s client mode with SGX guarded. As we know, in K8s client mode, the driver is deployed locally as an external client to the cluster. With client SGX mode, the executors running in K8S cluster are protected by SGX, and the driver running in the client is also protected by SGX.

-
cluster SGX mode: run jobs in k8s cluster mode with SGX guarded. As we know, in K8s cluster mode, the driver is deployed on the k8s worker nodes like executors. With cluster SGX mode, the driver and executors running in K8S cluster are protected by SGX.

-
-
There are two options to submit PPML jobs:
- use PPML CLI to submit jobs manually
- use helm chart to submit jobs automatically
Here we use k8s client mode and PPML CLI to run. Check other modes, please see PPML CLI Usage Examples. Alternatively, you can also use Helm to submit jobs automatically, see the details in Helm Chart Usage.
expand to see details of submitting SimpleQuery
-
enter the ppml container
docker exec -it bigdl-ppml-client-k8s bash -
run simplequery on k8s client mode
#!/bin/bash export secure_password=`openssl rsautl -inkey /ppml/password/key.txt -decrypt </ppml/password/output.bin` bash bigdl-ppml-submit.sh \ --master $RUNTIME_SPARK_MASTER \ --deploy-mode client \ --sgx-enabled true \ --sgx-driver-jvm-memory 1g \ --sgx-executor-jvm-memory 1g \ --driver-memory 1g \ --driver-cores 8 \ --executor-memory 1g \ --executor-cores 8 \ --num-executors 2 \ --conf spark.kubernetes.container.image=$RUNTIME_K8S_SPARK_IMAGE \ --name simplequery \ --verbose \ --class com.intel.analytics.bigdl.ppml.examples.SimpleQuerySparkExample \ local://$BIGDL_HOME/jars/bigdl-ppml-spark_$SPARK_VERSION-$BIGDL_VERSION.jar \ --inputPath /ppml/data/simplequery/people_encrypted \ --outputPath /ppml/data/simplequery/people_encrypted_output \ --inputPartitionNum 8 \ --outputPartitionNum 8 \ --inputEncryptModeValue AES/CBC/PKCS5Padding \ --outputEncryptModeValue AES/CBC/PKCS5Padding \ --primaryKeyPath /ppml/data/simplequery/keys/primaryKey \ --dataKeyPath /ppml/data/simplequery/keys/dataKey \ --kmsType EHSMKeyManagementService --kmsServerIP your_ehsm_kms_server_ip \ --kmsServerPort your_ehsm_kms_server_port \ --ehsmAPPID your_ehsm_kms_appid \ --ehsmAPIKEY your_ehsm_kms_apikey -
check runtime status: exit the container or open a new terminal
To check the logs of the Spark driver, run
sudo kubectl logs $( sudo kubectl get pod | grep "simplequery.*-driver" -m 1 | cut -d " " -f1 )To check the logs of a Spark executor, run
sudo kubectl logs $( sudo kubectl get pod | grep "simplequery-.*-exec" -m 1 | cut -d " " -f1 ) -
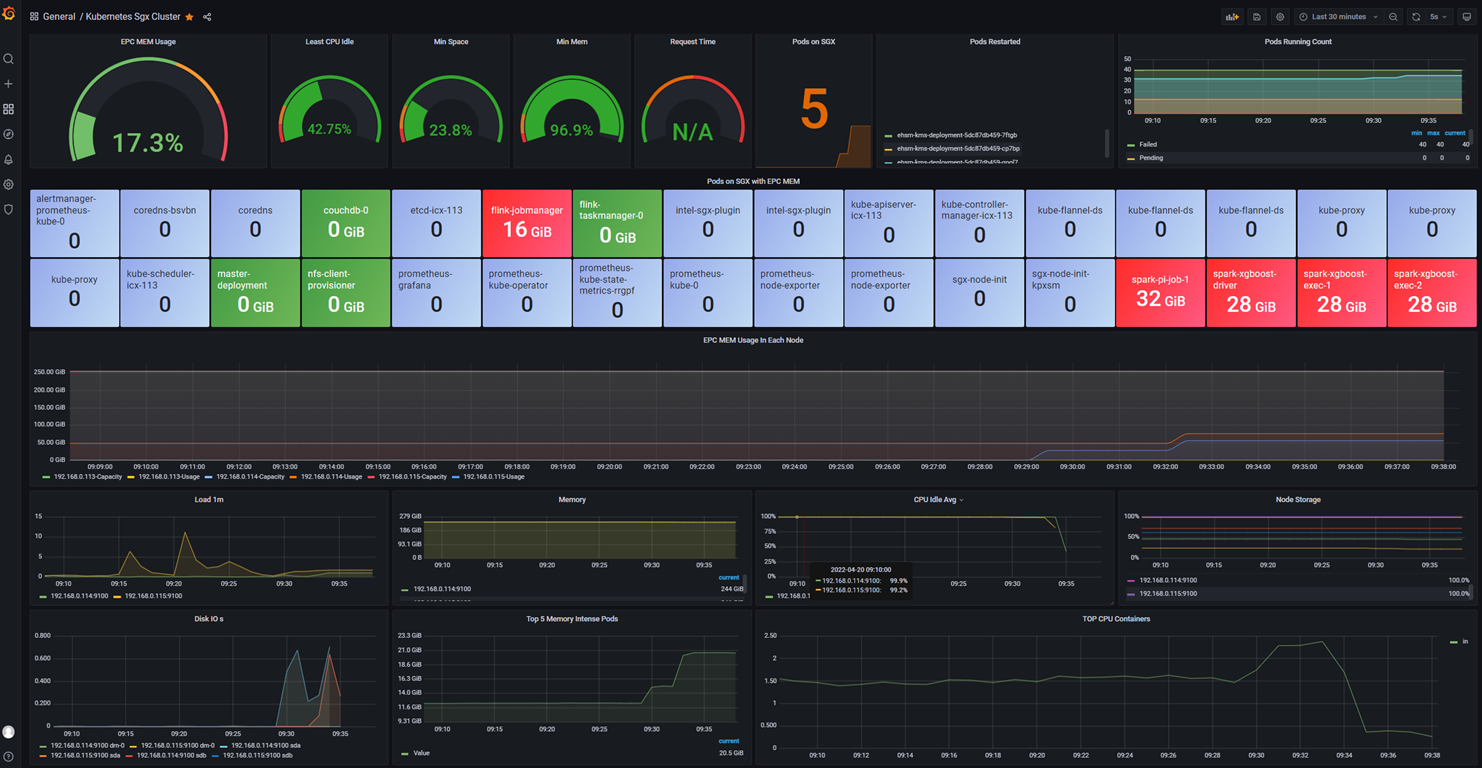
If you setup PPML Monitoring, you can check PPML Dashboard to monitor the status in http://kubernetes_master_url:3000
You can monitor spark events using the history server. The history server provides an interface to watch and log spark performance and metrics.
First, create a shared directory that can be accessed by both the client and the other worker containers in your cluster. For example, you can create an empty directory under the mounted nfs path or hdfs. The spark drivers and executors will write their event logs to this destination, and the history server will read logs here as well.
Second, enter your client container and edit $SPARK_HOME/conf/spark-defaults.conf, where the history server reads the configurations:
spark.eventLog.enabled true
spark.eventLog.dir <your_shared_dir_path> ---> e.g. file://<your_nfs_dir_path> or hdfs://<your_hdfs_dir_path>
spark.history.fs.logDirectory <your_shared_dir_path> ---> similar to spark.eventLog.dir
Third, run the below command and the history server will start to watch automatically:
$SPARK_HOME/sbin/start-history-server.sh
Next, when you run spark jobs, enable writing driver and executor event logs in java/spark-submit commands by setting spark conf like below:
...
--conf spark.eventLog.enabled=true \
--conf spark.eventLog.dir=<your_shared_dir_path> \
...
Starting spark jobs, you can find event log files at <your_shared_dir_path> like:
$ ls
local-1666143241860 spark-application-1666144573580
$ cat spark-application-1666144573580
......
{"Event":"SparkListenerJobEnd","Job ID":0,"Completion Time":1666144848006,"Job Result":{"Result":"JobSucceeded"}}
{"Event":"SparkListenerApplicationEnd","Timestamp":1666144848021}
You can use these logs to analyze spark jobs. Moreover, you are also allowed to surf from a web UI provided by the history server by accessing http://localhost:18080:

When the job is done, you can decrypt and read the result of the job. More details in Decrypt Job Result.
docker exec -i $KMSUTIL_CONTAINER_NAME bash -c "bash /home/entrypoint.sh decrypt $appid $apikey $input_path"
simplequery.e2e.mp4
In addition to the above Spark Pi and Python HelloWorld programs running locally, and simplequery application running on the k8s cluster, we also provide other examples including Trusted Data Analysis, Trusted ML, Trusted DL and Trusted FL. You can find these examples in more examples.
First, you need to create a PPMLContext, which wraps SparkSession and provides methods to read encrypted data files into plain-text RDD/DataFrame and write DataFrame to encrypted data files. Then you can read & write data through PPMLContext.
If you are familiar with Spark, you may find that the usage of PPMLConext is very similar to Spark. The explanations of PPMLContext configurations in the following can be found here.
-
create a PPMLContext with
appNameThis is the simplest way to create a
PPMLContext. When you don't need to read/write encrypted files, you can use this way to create aPPMLContext.scala
import com.intel.analytics.bigdl.ppml.PPMLContext val sc = PPMLContext.initPPMLContext("MyApp")
python
from bigdl.ppml.ppml_context import * sc = PPMLContext("MyApp")
If you want to read/write encrypted files, then you need to provide more information.
-
create a PPMLContext with
appName&ppmlArgsppmlArgsis ppml arguments in a Map,ppmlArgsvaries according to the kind of Key Management Service (KMS) you are using. Key Management Service (KMS) is used to generateprimaryKeyanddataKeyto encrypt/decrypt data. We provide 3 types of KMS ——SimpleKeyManagementService, EHSMKeyManagementService, and AzureKeyManagementService.Refer to KMS Utils to use KMS to generate
primaryKeyanddataKey, then you are ready to create PPMLContext withppmlArgs.-
For
SimpleKeyManagementService:scala
import com.intel.analytics.bigdl.ppml.PPMLContext val ppmlArgs: Map[String, String] = Map( "spark.bigdl.primaryKey.PK.kms.type" -> "SimpleKeyManagementService", "spark.bigdl.primaryKey.PK.kms.appId" -> "your_app_id", "spark.bigdl.primaryKey.PK.kms.apiKey" -> "your_api_key", "spark.bigdl.primaryKey.PK.material" -> "/your/primary/key/path/primaryKey" ) val sc = PPMLContext.initPPMLContext("MyApp", ppmlArgs)
python
from bigdl.ppml.ppml_context import * ppml_args = {"kms_type": "SimpleKeyManagementService", "app_id": "your_app_id", "api_key": "your_api_key", "primary_key_material": "/your/primary/key/path/primaryKey" } sc = PPMLContext("MyApp", ppml_args)
-
For
EHSMKeyManagementService:scala
import com.intel.analytics.bigdl.ppml.PPMLContext val ppmlArgs: Map[String, String] = Map( "spark.bigdl.primaryKey.PK.kms.type" -> "EHSMKeyManagementService", "spark.bigdl.primaryKey.PK.kms.ip" -> "your_server_ip", "spark.bigdl.primaryKey.PK.kms.port" -> "your_server_port", "spark.bigdl.primaryKey.PK.kms.appId" -> "your_app_id", "spark.bigdl.primaryKey.PK.kms.apiKey" -> "your_api_key", "spark.bigdl.primaryKey.PK.kms.material" -> "/your/primary/key/path/primaryKey" ) val sc = PPMLContext.initPPMLContext("MyApp", ppmlArgs)
python
from bigdl.ppml.ppml_context import * ppml_args = {"kms_type": "EHSMKeyManagementService", "kms_server_ip": "your_server_ip", "kms_server_port": "your_server_port" "app_id": "your_app_id", "api_key": "your_api_key", "primary_key_material": "/your/primary/key/path/primaryKey" } sc = PPMLContext("MyApp", ppml_args)
-
For
AzureKeyManagementServicethe parameter
clientIdis not necessary, you don't have to provide this parameter.scala
import com.intel.analytics.bigdl.ppml.PPMLContext val ppmlArgs: Map[String, String] = Map( "spark.bigdl.primaryKey.PK.kms.type" -> "AzureKeyManagementService", "spark.bigdl.primaryKey.PK.kms.vault" -> "key_vault_name", "spark.bigdl.primaryKey.PK.kms.clientId" -> "client_id", "spark.bigdl.primaryKey.PK.material" -> "/your/primary/key/path/primaryKey" ) val sc = PPMLContext.initPPMLContext("MyApp", ppmlArgs)
python
from bigdl.ppml.ppml_context import * ppml_args = {"kms_type": "AzureKeyManagementService", "vault": "your_azure_vault", "client_id": "your_azure_client_id", "primary_key_material": "/your/primary/key/path/primaryKey", } sc = PPMLContext("MyApp", ppml_args)
-
For
BigDLKeyManagementServicescala
import com.intel.analytics.bigdl.ppml.PPMLContext val ppmlArgs: Map[String, String] = Map( "spark.bigdl.primaryKey.PK.kms.type" -> "BigDLKeyManagementService", "spark.bigdl.primaryKey.PK.kms.ip" -> "your_server_ip", "spark.bigdl.primaryKey.PK.kms.port" -> "your_server_port", "spark.bigdl.primaryKey.PK.kms.user" -> "your_user_name", "spark.bigdl.primaryKey.PK.kms.token" -> "your_user_token", "spark.bigdl.primaryKey.PK.material" -> "your_precreated_primary_key_name", ) val sc = PPMLContext.initPPMLContext("MyApp", ppmlArgs)
python
from bigdl.ppml.ppml_context import * ppml_args = {"kms_type": "BigDLKeyManagementService", "kms_server_ip": "your_server_ip", "kms_server_port": "your_server_port", "kms_user_name": "your_user_name", "kms_user_token": "your_user_token", "primary_key_material": "your_precreated_primary_key_name", } sc = PPMLContext("MyApp", ppml_args)
-
-
create a PPMLContext with
sparkConf&appName&ppmlArgsIf you need to set Spark configurations, you can provide a
SparkConfwith Spark configurations to create aPPMLContext.scala
import com.intel.analytics.bigdl.ppml.PPMLContext import org.apache.spark.SparkConf val ppmlArgs: Map[String, String] = Map( "spark.bigdl.primaryKey.PK.kms.type" -> "SimpleKeyManagementService", "spark.bigdl.primaryKey.PK.kms.appId" -> "your_app_id", "spark.bigdl.primaryKey.PK.kms.apiKey" -> "your_api_key", "spark.bigdl.primaryKey.PK.material" -> "/your/primary/key/path/primaryKey", ) val conf: SparkConf = new SparkConf().setMaster("local[4]") val sc = PPMLContext.initPPMLContext(conf, "MyApp", ppmlArgs)
python
from bigdl.ppml.ppml_context import * from pyspark import SparkConf ppml_args = {"kms_type": "SimpleKeyManagementService", "app_id": "your_app_id", "api_key": "your_api_key", "primary_key_material": "/your/primary/key/path/primaryKey" } conf = SparkConf() conf.setMaster("local[4]") sc = PPMLContext("MyApp", ppml_args, conf)
To read/write data, you should set the CryptoMode:
plain_text: no encryptionAES/CBC/PKCS5Padding: for CSV, JSON and text fileAES_GCM_V1: for PARQUET onlyAES_GCM_CTR_V1: for PARQUET only
To write data, you should set the write mode:
overwrite: Overwrite existing data with the content of dataframe.append: Append the content of the dataframe to existing data or table.ignore: Ignore the current write operation if data/table already exists without any error.error: Throw an exception if data or table already exists.errorifexists: Throw an exception if data or table already exists.
scala
import com.intel.analytics.bigdl.ppml.crypto.AES_CBC_PKCS5PADDING
// save df in ciphertext
sc.write(dataFrame = df, cryptoMode = AES_CBC_PKCS5PADDING).csv(path = ...)
// load and decrypt encrypted file
val decryptedDF = sc.read(cryptoMode = AES_CBC_PKCS5PADDING).csv(path = ...)python
from bigdl.ppml.ppml_context import *
# save df in ciphertext
sc.write(dataframe = df, crypto_mode = AES_CBC_PKCS5PADDING).csv(path = ...)
# load and decrypt encrypted file
decrypted_df = sc.read(crypto_mode = AES_CBC_PKCS5PADDING).csv(path = ...)expand to see the examples of reading/writing CSV, PARQUET, JSON and text file
The following examples use sc to represent an initialized PPMLContext
read/write CSV file
scala
import com.intel.analytics.bigdl.ppml.PPMLContext
import com.intel.analytics.bigdl.ppml.crypto.{AES_CBC_PKCS5PADDING, PLAIN_TEXT}
// read a plain csv file and return a DataFrame
val plainCsvPath = "/plain/csv/path"
val df1 = sc.read(cryptoMode = PLAIN_TEXT).option("header", "true").csv(plainCsvPath)
// write a DataFrame as a plain csv file
val plainOutputPath = "/plain/output/path"
sc.write(df1, PLAIN_TEXT)
.mode("overwrite")
.option("header", "true")
.csv(plainOutputPath)
// read a encrypted csv file and return a DataFrame
val encryptedCsvPath = "/encrypted/csv/path"
val df2 = sc.read(cryptoMode = AES_CBC_PKCS5PADDING).option("header", "true").csv(encryptedCsvPath)
// write a DataFrame as an encrypted csv file
val encryptedOutputPath = "/encrypted/output/path"
sc.write(df2, AES_CBC_PKCS5PADDING)
.mode("overwrite")
.option("header", "true")
.csv(encryptedOutputPath)python
# import
from bigdl.ppml.ppml_context import *
# read a plain csv file and return a DataFrame
plain_csv_path = "/plain/csv/path"
df1 = sc.read(CryptoMode.PLAIN_TEXT).option("header", "true").csv(plain_csv_path)
# write a DataFrame as a plain csv file
plain_output_path = "/plain/output/path"
sc.write(df1, CryptoMode.PLAIN_TEXT)
.mode('overwrite')
.option("header", True)
.csv(plain_output_path)
# read a encrypted csv file and return a DataFrame
encrypted_csv_path = "/encrypted/csv/path"
df2 = sc.read(CryptoMode.AES_CBC_PKCS5PADDING).option("header", "true").csv(encrypted_csv_path)
# write a DataFrame as an encrypted csv file
encrypted_output_path = "/encrypted/output/path"
sc.write(df2, CryptoMode.AES_CBC_PKCS5PADDING)
.mode('overwrite')
.option("header", True)
.csv(encrypted_output_path)read/write PARQUET file
scala
import com.intel.analytics.bigdl.ppml.PPMLContext
import com.intel.analytics.bigdl.ppml.crypto.{AES_GCM_CTR_V1, PLAIN_TEXT}
// read a plain parquet file and return a DataFrame
val plainParquetPath = "/plain/parquet/path"
val df1 = sc.read(PLAIN_TEXT).parquet(plainParquetPath)
// write a DataFrame as a plain parquet file
plainOutputPath = "/plain/output/path"
sc.write(df1, PLAIN_TEXT)
.mode("overwrite")
.parquet(plainOutputPath)
// read an encrypted parquet file and return a DataFrame
val encryptedParquetPath = "/encrypted/parquet/path"
val df2 = sc.read(AES_GCM_CTR_V1).parquet(encryptedParquetPath)
// write a DataFrame as an encrypted parquet file
val encryptedOutputPath = "/encrypted/output/path"
sc.write(df2, AES_GCM_CTR_V1)
.mode("overwrite")
.parquet(encryptedOutputPath)python
# import
from bigdl.ppml.ppml_context import *
# read a plain parquet file and return a DataFrame
plain_parquet_path = "/plain/parquet/path"
df1 = sc.read(CryptoMode.PLAIN_TEXT).parquet(plain_parquet_path)
# write a DataFrame as a plain parquet file
plain_output_path = "/plain/output/path"
sc.write(df1, CryptoMode.PLAIN_TEXT)
.mode('overwrite')
.parquet(plain_output_path)
# read an encrypted parquet file and return a DataFrame
encrypted_parquet_path = "/encrypted/parquet/path"
df2 = sc.read(CryptoMode.AES_GCM_CTR_V1).parquet(encrypted_parquet_path)
# write a DataFrame as an encrypted parquet file
encrypted_output_path = "/encrypted/output/path"
sc.write(df2, CryptoMode.AES_GCM_CTR_V1)
.mode('overwrite')
.parquet(encrypted_output_path)read/write JSON file
scala
import com.intel.analytics.bigdl.ppml.PPMLContext
import com.intel.analytics.bigdl.ppml.crypto.{AES_CBC_PKCS5PADDING, PLAIN_TEXT}
// read a plain JSON file and return a DataFrame
val plainJsonPath = "/plain/JSON/path"
val df1 = sc.read(PLAIN_TEXT).json(plainJsonPath)
// write a DataFrame as a plain JSON file
val plainOutputPath = "/plain/output/path"
sc.write(df1, PLAIN_TEXT)
.mode("overwrite")
.json(plainOutputPath)
// read an encrypted JSON file and return a DataFrame
val encryptedJsonPath = "/encrypted/parquet/path"
val df2 = sc.read(AES_CBC_PKCS5PADDING).json(encryptedJsonPath)
// write a DataFrame as an encrypted parquet file
val encryptedOutputPath = "/encrypted/output/path"
sc.write(df2, AES_CBC_PKCS5PADDING)
.mode("overwrite")
.json(encryptedOutputPath)python
# import
from bigdl.ppml.ppml_context import *
# read a plain JSON file and return a DataFrame
plain_json_path = "/plain/JSON/path"
df1 = sc.read(CryptoMode.PLAIN_TEXT).json(plain_json_path)
# write a DataFrame as a plain JSON file
plain_output_path = "/plain/output/path"
sc.write(df1, CryptoMode.PLAIN_TEXT)
.mode('overwrite')
.json(plain_output_path)
# read an encrypted JSON file and return a DataFrame
encrypted_json_path = "/encrypted/parquet/path"
df2 = sc.read(CryptoMode.AES_CBC_PKCS5PADDING).json(encrypted_json_path)
# write a DataFrame as an encrypted parquet file
encrypted_output_path = "/encrypted/output/path"
sc.write(df2, CryptoMode.AES_CBC_PKCS5PADDING)
.mode('overwrite')
.json(encrypted_output_path)read textfile
scala
import com.intel.analytics.bigdl.ppml.PPMLContext
import com.intel.analytics.bigdl.ppml.crypto.{AES_CBC_PKCS5PADDING, PLAIN_TEXT}
// read from a plain csv file and return a RDD
val plainCsvPath = "/plain/csv/path"
val rdd1 = sc.textfile(plainCsvPath) // the default cryptoMode is PLAIN_TEXT
// read from an encrypted csv file and return a RDD
val encryptedCsvPath = "/encrypted/csv/path"
val rdd2 = sc.textfile(path=encryptedCsvPath, cryptoMode=AES_CBC_PKCS5PADDING)python
# import
from bigdl.ppml.ppml_context import *
# read from a plain csv file and return a RDD
plain_csv_path = "/plain/csv/path"
rdd1 = sc.textfile(plain_csv_path) # the default crypto_mode is "plain_text"
# read from an encrypted csv file and return a RDD
encrypted_csv_path = "/encrypted/csv/path"
rdd2 = sc.textfile(path=encrypted_csv_path, crypto_mode=CryptoMode.AES_CBC_PKCS5PADDING)For more usage with PPMLContext Python API, please refer to PPMLContext Python API.
As for multi-party computation scenarios where multiple data sources, KMSs and keys exist, you can also use the initPPMLContext method to automatically initialize PPML Context with support for multiple key management services and data sources.
You just need to specify the configurations of one or more primary keys as below:
- Primary key is applied to encrypt and decrypt data key, and one primary key can be bound to multiple data keys. In PPMLContext, a primary key can be provided in two ways, a plaintext base64 string or a key generated by KMS:
-
spark.bigdl.primaryKey.[PrimaryKeyName].plainText: a plaintext base64 key string, which PPMLContext will use to encrypt the data key directly, and this is only for demo purposes and not recommended in production in consideration of security.
-
spark.bigdl.primaryKey.[PrimaryKeyName].kms.type: type of an existing KMS instance, e.g.
SimpleKeyManagementService,EHSMKeyManagementService,AzureKeyManagementServiceorBigDLKeyManagementService. PPMLContext will retrieve a pre-generated primary key that is managed by the KMS.The
[PrimaryKeyName]field above can be any string, and in a multi-party computation scenario, you can configure multiple primary keys with different names for different parties. (Note: since Trusted SimpleQuery With Multiple Data source/KMS is an implementation example of business logic, primary-key names in it cannot be specified freely and must beAmyPKandBobPK.)
- Type-specific parameters for each KMS instance:
-
For
SimpleKeyManagementService:spark.bigdl.primaryKey.[PrimaryKeyName].material: the encrypted primary key path of SimpleKMS.
spark.bigdl.primaryKey.[PrimaryKeyName].kms.appId: APPID of SimpleKMS.
spark.bigdl.primaryKey.[PrimaryKeyName].kms.apiKey: APIKEY of SimpleKMS.
-
For
EHSMKeyManagementService:spark.bigdl.primaryKey.[PrimaryKeyName].material: the encrypted primary key path of EHSM.
spark.bigdl.primaryKey.[PrimaryKeyName].kms.ip: EHSM service IP.
spark.bigdl.primaryKey.[PrimaryKeyName].kms.port: EHSM port number.
spark.bigdl.primaryKey.[PrimaryKeyName].kms.appId: EHSM APPID.
spark.bigdl.primaryKey.[PrimaryKeyName].kms.apiKey: EHSM APIKEY.
-
For
AzureKeyManagementService:spark.bigdl.primaryKey.[PrimaryKeyName].material: the encrypted primary key path of Azure KMS.
spark.bigdl.primaryKey.[PrimaryKeyName].kms.vault: Azure KMS KeyVault.
spark.bigdl.primaryKey.[PrimaryKeyName].kms.clientId: Azure KMS clientId.
-
For
BigDLKeyManagementService:spark.bigdl.primaryKey.[PrimaryKeyName].material: primary key name of BigDL KMS.
spark.bigdl.primaryKey.[PrimaryKeyName].kms.ip: BigDL KMS service IP.
spark.bigdl.primaryKey.[PrimaryKeyName].kms.port: BigDL KMS port number.
spark.bigdl.primaryKey.[PrimaryKeyName].kms.user: BigDL KMS user name.
spark.bigdl.primaryKey.[PrimaryKeyName].kms.token: BigDL KMS user token.
An implementation can be seen in Trusted SimpleQuery With Multiple Data source/KMS. You can follow the example to develop your multi-party computation application.