Welcome 👋 to our MLOps repository!
This documentation describes IBM's MLOps flow implemented using services in IBM's Cloud Pak for Data stack. This asset is specifically created to enable the rapid and effortless creation of end-to-end machine learning workflows, while simultaneously exhibiting the strengths of the products found in our Cloud Pak for Data stack.
We understand that organizations may come with unique ML use cases, which is why - alongside simplicity - we've placed a strong emphasis on modularity. Our solution provides a full fundamental workflow documentation, and comes with plug-and-play integration for custom-built models (PyTorch, Tensorflow, Keras...) and CI tests. Additionally, our project is built using Watson Pipelines, which offers extensive drag-and-drop modularity, providing you with the flexibility and customization options you need to create tailored ML solutions that perfectly fit your organization's unique requirements.

Fig. 1.: Architecture of the MLOps flow
Throughout the demo described in detail, we use a biased version of the German Credit Risk dataset. To predict credit risk in the setup instructions below, we leverage an SKLearn Pipeline in which we place, train and test a LightGBM model. (Alternatively you may provide a custom-built model or choose one from /custom_models). The code is written in Python 3.9 and requires access to IBM Watson Studio, Watson Machine Learning, Watson Knowledge Catalog, and Watson OpenScale. The architecture consists of three stages: development, pre-prod, and prod. The process includes: receiving code updates, training, deploying, and monitoring models.
In addition to common metrics (e.g. accuracy), it is crucial to ensure fairness and ethical considerations in the decision-making process. To address this, monitoring and testing must be conducted on a regular basis to identify and mitigate any potential biases in the model.
In order to use the above asset we need to have access to have an IBM environment with authentication. IBM Cloud Account with following services:
- IBM Watson Studio
- IBM Watson Machine Learning
- IBM Watson Knowledge Catalog with Factsheets and Model Inventory
- IBM Watson OpenScale
Please ascertain you have appropriate access in all the services.
The runs are also governed by the amount of capacity unit hours (CUH) you have access to. If you are running on the free plan please refer to the following links:
- https://cloud.ibm.com/catalog/services/watson-studio
- https://cloud.ibm.com/catalog/services/watson-machine-learning
- https://cloud.ibm.com/catalog/services/watson-openscale
- https://cloud.ibm.com/catalog/services/watson-knowledge-catalog
This repo has two branches, master and pre-prod. The master branch is served as the dev branch, and receives direct commits from the linked CP4D project. When a pull request is created to merge the changes into the pre-prod branch, Jenkins will automatically start the CI tests.
In this repo we demonstrate three steps in the MLOps process:
- Development: orchestrated experiments and generate source code for pipelines
- Pre-prod: receives code updates from dev stage and contain CI tests to make sure the new code/model integrates well, trains, deploys and monitors the model in the pre-prod deployment space to validate the model. The validated model can be deployed to prod once approved by the model validator.
- Prod: deploys the model in the prod environment and monitors it, triggers retraining jobs (eg. restart pre-prod pipeline or offline modeling)
You create a project to work with data and other resources to achieve a particular goal, such as building a model or integrating data.
(
- Click New project on the home page or on your Projects page.
- Create an empty project.
- On the New project screen, add a name. Make it short but descriptive.
- If appropriate for your use case, mark the project as sensitive. The project has a sensitive tag and project collaborators can't move data assets out of the project. You cannot change this setting after the project is created.
- Choose an existing object storage service instance or create a new one. Click Create. You can start adding resources to your project.
Along with the creation of a project, a bucket in your object storage instance will be created. This bucket will look like [PROJECT_NAME]-donotdelete....
You can use this bucket through out this project, however we recommend creating a separate bucket in which we will store the dataset, train/test split et cetera.
🪣 See how you can setup your own Bucket in COS
-
Navigate to your COS as explain in Step 3 above.
-
Click on buckets. Create a bucket.

- Click "Customise Bucket".

- Name the Bucket
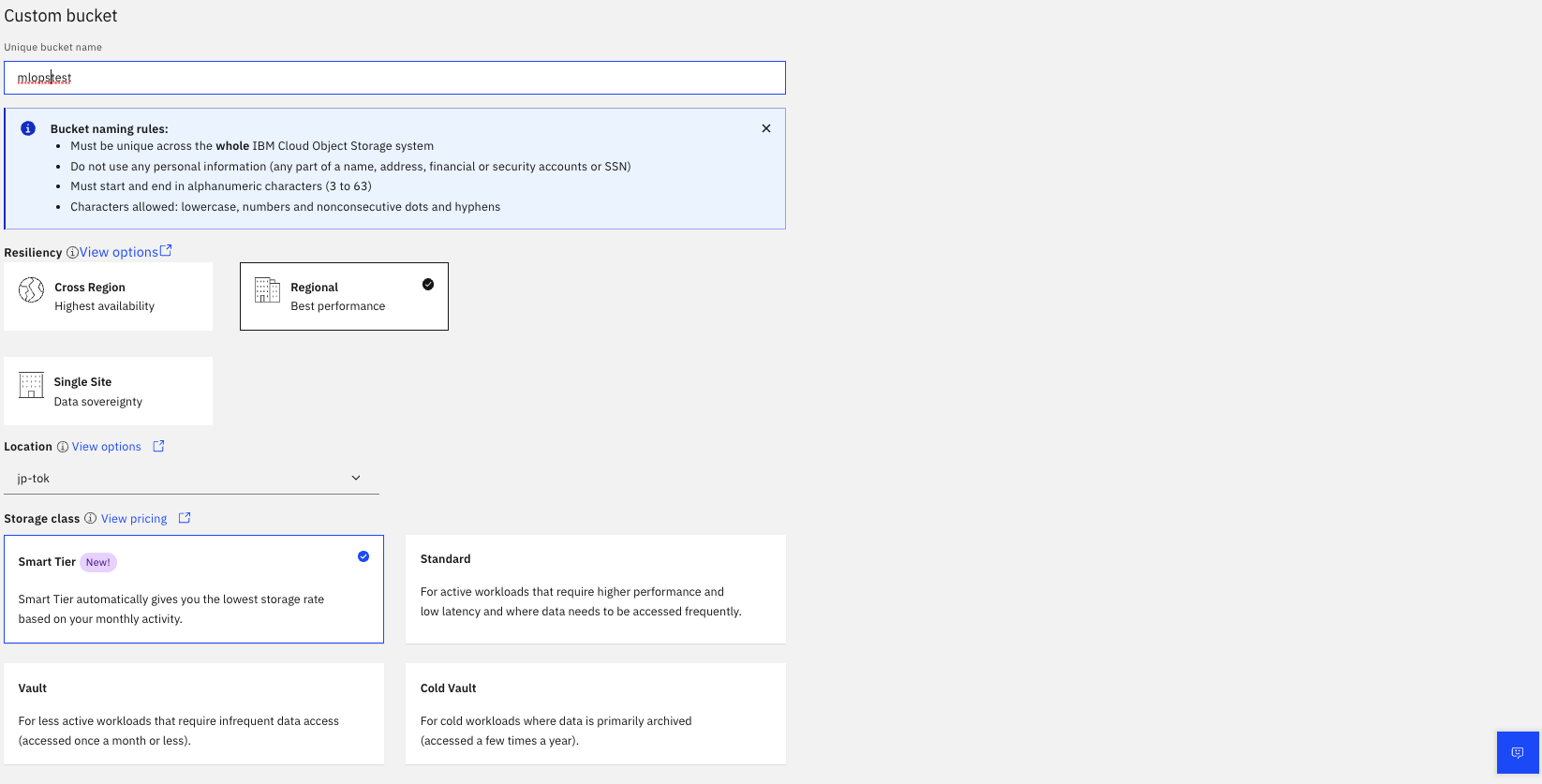
- Click create.
Now download the dataset (german_credit_data_biased_training.csv) and place it in the bucket you chose to use for the rest of this tutorial.
For IBM Watson Machine Learning, we will need three spaces:
- MLOps_dev : Dev Space to deploy your models and test before being pushed to the pre-prod
- MLOps_preprod : Pre-prod Space to deploy and test and validate your models. The Validator uses this environment before giving a go ahead to push the models in production.
- MLOps_prod : Production Space to deploy your validated models and monitor it.
In this section, we will first setup the custom Python environments, collect necessary credentials, upload the notebooks, and modify them. The pre-defined environments (henceforth called software configuration) do not contain all the Python packages we require. Therefore we will create custom software configurations prior to adding the notebooks.
Some of the notebooks require quite a few dependencies, which should not be manually installed via pip in each notebook every time. To avoid doing that, we will create software configurations.
⚠️ Click here if you do not know how to customize environments in Watson Studio
- Navigate to your Project overview, select the "Manage" tab and select "Environments" in the left-hand menu. Here, check that no runtime is active for the environment template that you want to change. If a runtime is active, you must stop it before you can change the template.
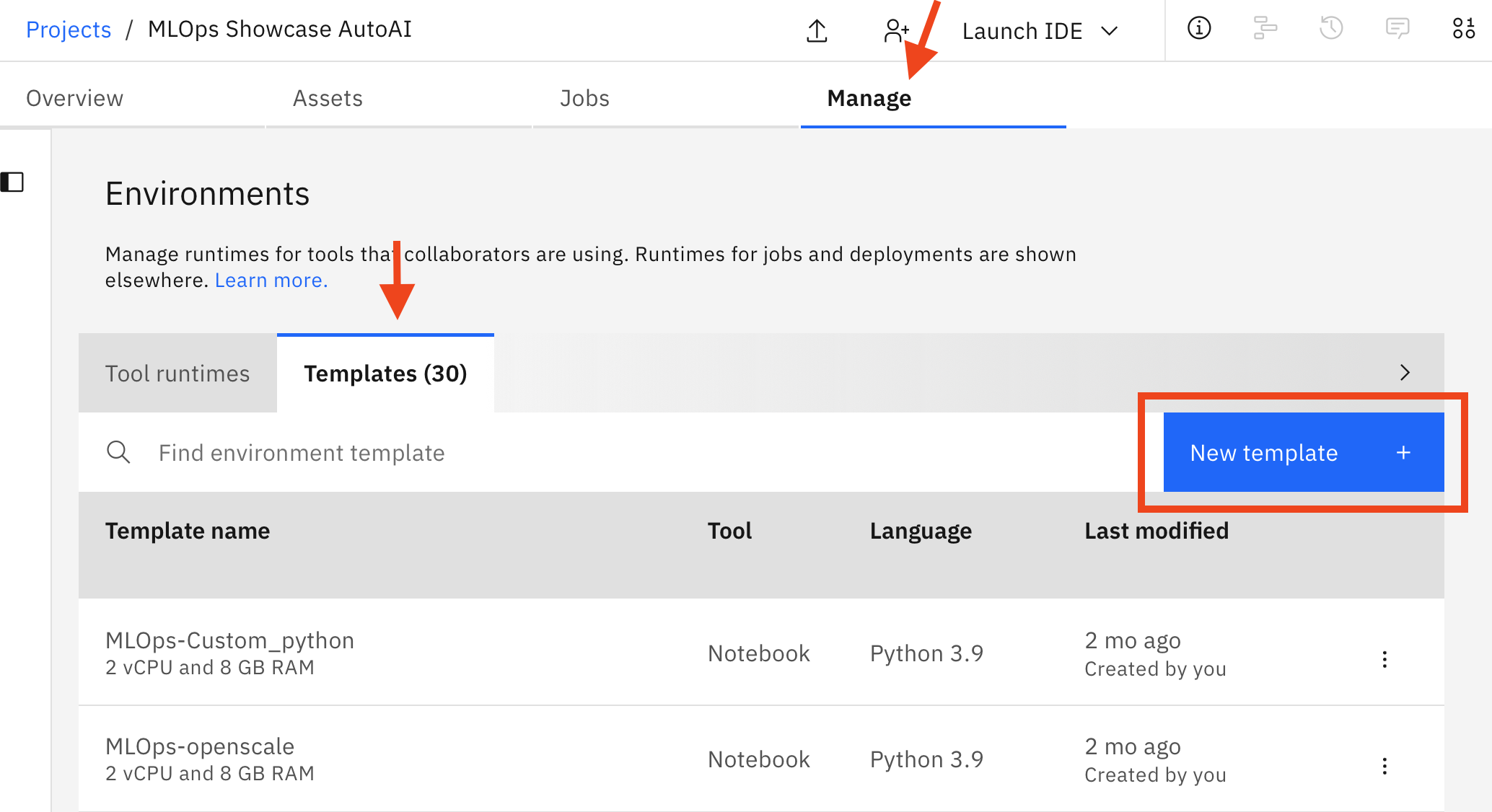
- Under Templates click
New template +and give it a name (for the pipeline preferably one of those described below), specify a hardware configuration (we recommend2 vCPU and 8GB RAMfor this project, but you can scale up or down depending on your task). When you are done clickCreate.
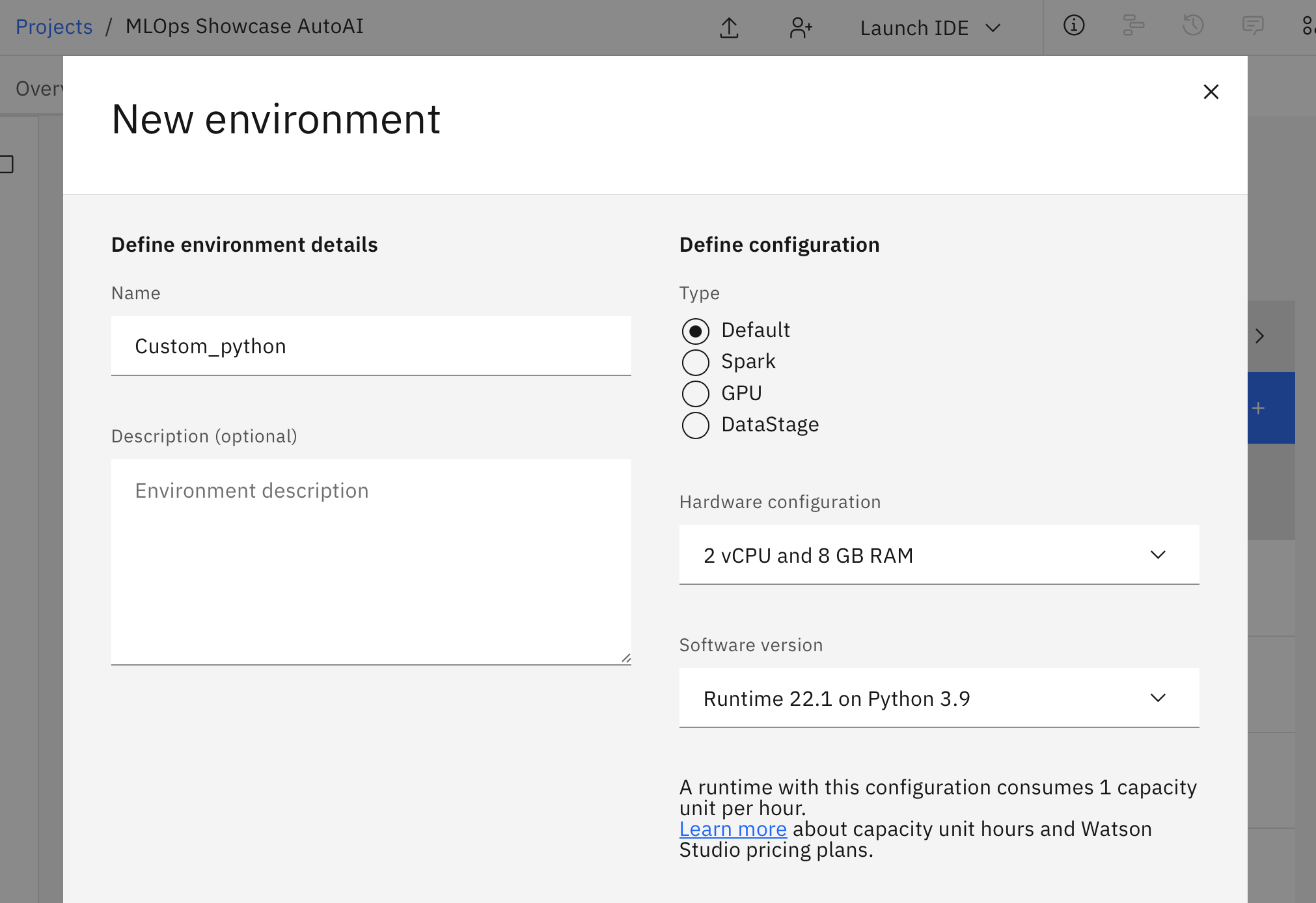
- You can now create a software customization and specify the libraries to add to the standard packages that are available by default.
(For more details, check out Adding a customization in the Documentation)
- Use Python 3.9
- Modify the
pippart of the Python environment customisation script below:
# Modify the following content to add a software customization to an environment.
# To remove an existing customization, delete the entire content and click Apply.
# The customizations must follow the format of a conda environment yml file.
# Add conda channels below defaults, indented by two spaces and a hyphen.
channels:
- defaults
# To add packages through conda or pip, remove the # on the following line.
dependencies:
# Add conda packages here, indented by two spaces and a hyphen.
# Remove the # on the following line and replace sample package name with your package name:
# - a_conda_package=1.0
# Add pip packages here, indented by four spaces and a hyphen.
# Remove the # on the following lines and replace sample package name with your package name.
- pip:
[ADD CUSTOMISATION PACKAGES HERE]
Environments used in this asset:
Custom_python environment
- pip:
- tensorflow-data-validation
- ibm_watson_studio_pipelines
pipeline_custom environment
- pip:
- ibm_watson_studio_pipelines
- ibm-aigov-facts-client
openscale environment
- pip:
- ibm_cloud_sdk_core
- ibm_watson_openscale
- ibm_watson_studio_pipelines
- ibm-aigov-facts-client
Before you run a notebook you need to obtain the following credentials and add the COS credentials to the beginning of each notebook. The Cloud API key must not be added to the notebooks since it is passed through the pipeline later.
a) The basic requirement is to get your IBM Cloud API Key (CLOUD_API_KEY) for all the pipelines.
❓ Where can I create/generate an API Key?
-
Navigate to https://cloud.ibm.com
-
(On the top right) Select Manage > Access(IAM).
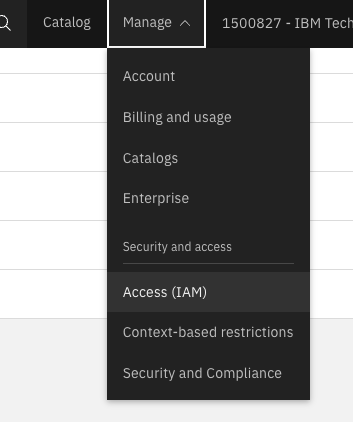
- Click on the API keys and create new API Key.

- Name the API Key and Copy or Download it.
b) Secondly you will need the following IBM Cloud Object Storage (COS) related variables, which will allow the notebooks to interact with your COS Instance.
The variables are:
Universal
AUTH_ENDPOINT= "https://iam.cloud.ibm.com/oidc/token"
Project Bucket (auto-generated e.g. "mlops-donotdelete-pr-qxxcecxi1d")
ENDPOINT_URL= "https://s3.private.us.cloud-object-storage.appdomain.cloud"API_KEY_COS= "xx"BUCKET_PROJECT_COS= "mlops-donotdelete-pr-qxxcecxi1dtw94"
MLOps Bucket (e.g. "mlops-asset")
ENDPOINT_URL_MLOPS= "https://s3.jp-tok.cloud-object-storage.appdomain.cloud"API_KEY_MLOPS= "xx"CRN_MLOPS= "xx"BUCKET_MLOPS= "mlops-asset"
❓ Where can I find these credentials for Cloud Object Storage?
- Go to cloud.ibm.com and select the account from the drop down.
- Go to Resource list by either clicking on the left hand side button or https://cloud.ibm.com/resources.
- Go to Storage and select the Cloud Object Storage instance that you want to use.
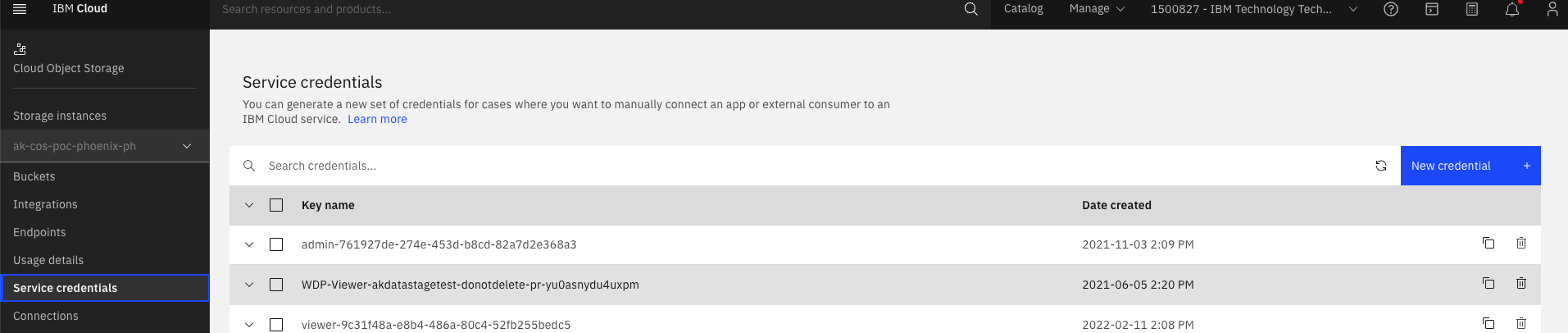
- Select "Service Credentials" and Click "New Credential:
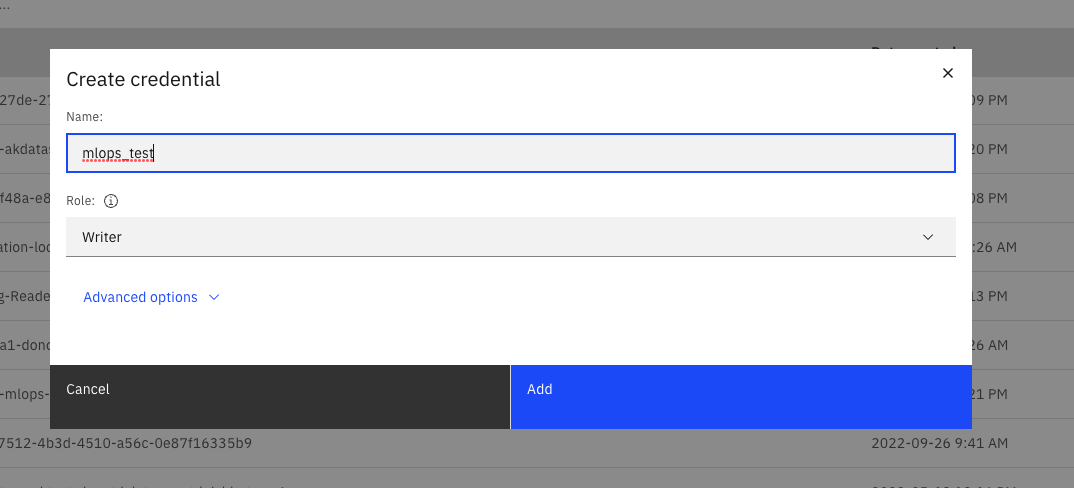
- Name the credential and hit Add.
- Go to the Saved credential and click to reveal your credential. You can use these values to fill the variables

You will need to define those variables at the top level of each notebook. Here is an example:
## PROJECT COS
AUTH_ENDPOINT = "https://iam.cloud.ibm.com/oidc/token"
ENDPOINT_URL = "https://s3.private.us.cloud-object-storage.appdomain.cloud"
API_KEY_COS = "xyz"
BUCKET_PROJECT_COS = "mlops-donotdelete-pr-qxxcecxi1dtw94"
##MLOPS COS
ENDPOINT_URL_MLOPS = "https://s3.jp-tok.cloud-object-storage.appdomain.cloud"
API_KEY_MLOPS = "xyz"
CRN_MLOPS = "xyz"
BUCKET_MLOPS = "mlops-asset"Alternatively, to make things easier, you may set them as Global Pipeline Parameters. This will allow you to e.g. switch the COS Bucket you are using without having to edit mulitple notebooks. Instead, you will only have to edit the parameter. Taking advantage of this feature will prove itself useful when using multiple pipelines later on.
The parameter strings should look like the example below in order for the notebooks to extract the correct values. Prepare one for your manually created Bucket and one for the Bucket attached to the project space.
{"API_KEY": "abc", "CRN": null, "AUTH_ENDPOINT": "https://iam.cloud.ibm.com/oidc/token", "ENDPOINT_URL": "https://s3.private.us.cloud-object-storage.appdomain.cloud", "BUCKET": "mlopsshowcaseautoai-donotdelete-pr-diasjjegeind"}Now you are ready to start!
This section describes how you can add the notebooks that take care of data connection, validation and preparation, as well as model training and deployment.
When this asset was created from scratch, it was laid out for our CPDaaS solution. However, there are slight - but for this project relevant - differences between the two including the absence of a file system and a less refined Git integration in CPDaaS. We are currently weighing the pros and cons of two approaches: Highlighting points of this documentation where CPDaaS is limited (including a work-around), or offering a separate repository.
The Git integration within CPDaaS is not as advanced as that found in our On-Prem solution. As long as that is the case, the notebooks found in the repository must be manually added to the project space.
💻 Manually adding a notebook to the project space
Download the repository to your local machine and navigate to your project space. On the asset tab, click New Asset +.
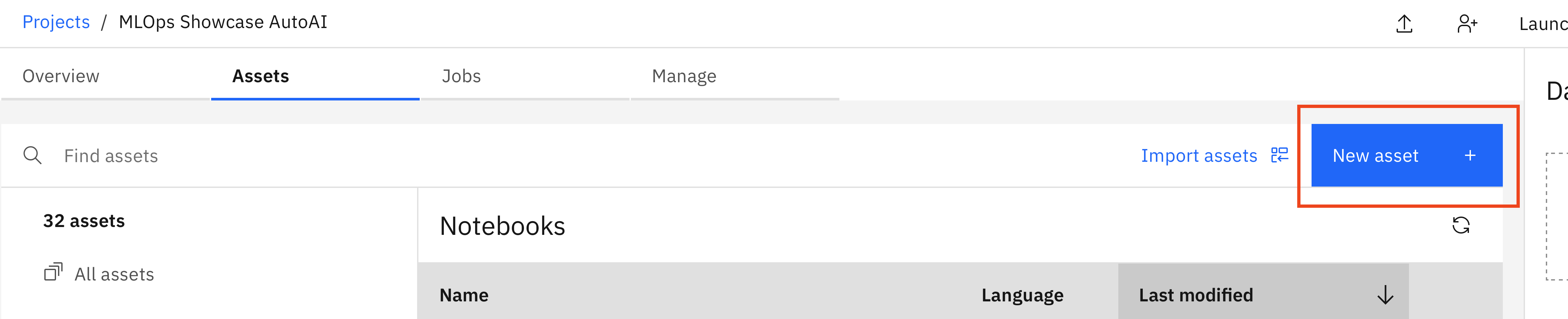
In the tool selection, select Jupyter notebook editor. Upload the desired notebook. A name will automatically be assigned based on the filename. Make sure to select our previously added Software Configuration Custom_python as the environment to be used for the notebook.

Repeat this procedure for all notebooks.
Note: As previously mentioned, CPDaaS does not come with a filesystem. The only efficient way to include utility scripts (see utility scripts) to e.g. handle catalog operations is to clone the repository manually from the notebook. This has been documented in each notebook. The corresponding cells are commented out at the top level of each notebook and must only be uncommented when operating on CPDaaS.

tbd
In order to move a Notebook from a project space to a deployment space, you will have to create a Notebook Job. Notebook Jobs represent non-interactive executables of a snapshot your notebook. When creating a Notebook Job you are offered many options the choice of a Software Configuration (virtual-env), Notifications, and Scheduling. Most importantly you are offered the option to set a Notebook Job to a hard-set version of the Notebook, or to always use the "Latest Version". With the latter, the Notebook Job is always updated automatically subsequent to saving a Notebook.
⚠️ How to create a WS Notebook Job
In an earlier version of Watson Studio Pipelines, you were able to drag a Run notebook block into the canvas to use as pipeline node. This functionality has been replaced with the Run notebook job block.
Prior to selecting a Notebook within the Settings of the Run notebook job block, you have to create a notebook job from the Project Space View under the Assets tab.

For the MLOps workflow to work as intended, it is important that you select Latest as the notebook Version for your notebook job. Otherwise, the notebook job block in your pipeline will be set to a specific previous version of the notebook, therefore changes in your code would not affect your pipeline.

However, even when having selected Latest as the notebook version to use for your notebook job, you will have to select File > Save Version after performing code changes in your notebook. Only then will the notebook register the changes.
To check the log and debug a pipeline: When the pipeline is running, double click on the node that is currently running to open Node Inspector, as shown in the below image. The log will contain all the notebook run status, the prints and errors where the notebook fails.

For this section you need to know how to create a WS Pipeline and how to correctly setup Notebook Jobs, which you will need to add Notebooks to a Pipeline. Check out the following toggleable sections to learn how to do that.
⚠️ How to create a WS Pipeline
In your CP4D project, click the blue button New Asset +. Then find Pipelines
Select Pipelines and give the pipeline a name.
Once the pipeline is created, you will see the pipeline edit menu and the palette on the left.
Expand the Run section and drag and drop the Run notebook block.
Double click the block to edit the node.
Offline modeling includes the usually data exploration and data science experiments. In this step, you can try different data manipulation, feature engineering and machine learning models.
The output of this stage is code assets, for example Python scripts or Jupyter notebooks that can be used as blocks in the pipelines.
In this example, the output scripts are Python scripts in Jupyter notebooks. They are version controled with Git, as shown in this repository, and serve as components in the pre-prod pipeline.
You can experiment with an orchestrated dev pipeline, which would include
-
Data connection and validation
-
Data preparation
-
Model training and evaluation
-
Model deployment
-
Model validation (optional)
Below is a dev pipeline in Watson Studio Pipeline:

This notebook source code can be found in connect_and_validate_data.ipynb.
It does the following:
- Load the training data
german_credit_risk.csvfrom cloud object storage (COS) - Data Validation. It comprises of the folllowing steps:
- Split the Data
- Generate Training Stats on both Splits
- Infer Schema on both Splits
- Check for data anomalies
This notebook source code can be found in data_preparation.ipynb, which does the following:
- Load train and test data from COS and split the X and y columns
- Encode features
- Save processed train and test data to COS
This notebook source code can be found in train_models.ipynb, which does the following:
- Load train and test data from COS, split train to train and validation data
- Load the pre-processing pipeline
- Train the model
- Save train and val loss to COS
- Calculate AUC-ROC
- Store the model in the project
- Track the model runs and stages with AI Factsheets
This notebook source code can be found in deploy_model.ipynb, which does the following:
- Load the trained mode from model registry
- Promote the model to a deployment space and deploy the model
- Test the endpoint
By changing the input to this notebook, the model can be deployed to dev, pre-prod and prod spaces.
When the Jupyter notebooks have a change committed and a pull request is made, Jenkins will start the CI tests.
The source code is stored in the jenkins directory and the documentation can be viewed here
As with any other MLOps pipeline, you should rigorously check whether or not your current model meets all the requirements you defined. In order to test this, we added a folder containing a small repertoire of CI tests which you can find here.
It is the overarching idea that a Data Scientist works primarily with the Notebooks themselves and manually invokes the development pipeline in order to initially test their work. The updated Notebooks should only be committed and pushed to the repository if the development pipeline completes successfully.
Therefore we suggest that you use the CI test repertoire to the extend that you can. Add tests that you would like to have to the end of your development pipeline in a plug&play manner. You may of course want to edit those CI test notebooks to set certain thresholds or even write your own tests.
Examples:
- Pipeline component integration test: run the pipeline in dev environment to check if it successfully runs.
- deserialize_artifact.ipynb will download the model stored in your COS Bucket. It will be deserialized and loaded into memory which is tested by scoring a few rows of your test data. This test is thus ensuring successful serialization. You may extend this test by checking the size of the model in memory or the size of the serialized model in storage and set a threshold, in order for the pipeline to fail when your model exceeds a certain size.
- model_convergence.ipynb will download the pickled training and validation loss data from your COS Bucket. It ensures that the training loss is continuously decreasing. You may extend this test by analysing training and validation loss to e.g. avoid serious underfitting or overfitting of the model.
-
Behaviour Tests
- Invariance
- Directionality
- Minimum functionality
-
Adversarial Tests
- Check to see if the model can be affected by direct adversarial attacks
-
Regression Tests
- Check specific groups within the test set to ensure performance is retained in this group after retraining
-
Miscellaneous Tests
- Test input data scheme
- Test with unexpected input types (null / Nan)
- Test output scheme is as expected
- Test output errors are handled correctly
After the CI tests passed, the admin/data science lead will merge the changes and Jenkins will trigger the following pre-prod pipeline:

It runs the notebook connect_and_validate_data.ipynb with:
Environment
pipeline_custom
Input params
cloud_api_key, Select from pipeline parameter
training_file_name, String
Output params
anomaly_status, Bool
files_copied_in_cos, Bool
We define a pipeline parameter cloud_api_key to avoid having the API key hardcoded in the pipeline:
[TO DO: insert picture here]
This block is followed by a Val check condition:

It runs the notebook data_preparation.ipynb
Environment
pipeline_custom
Input params
cloud_api_key, Select from pipeline parameter
Output params
data_prep_done, Bool
This block is followed by a prep check condition:

It runs the notebook train_models.ipynb
In WS Pipeline you can assign input to be the output from another node. To do this, select the folder icon next to environment variables:

Then select the node and the output you need

Environment
pipeline_custom
Input params
feature_pickle, String
apikey, Select from pipeline parameter
model_name, String
deployment_name, String
Output params
training_done, Bool
auc_roc, Float
model_name, String
deployment_name, String
model_id, String
project_id, String
This block is followed by a Train check condition:

It runs the notebook deploy_model.ipynb
By changing the input parameter space_id, we can set the model to deploy to the pre-prod deployment space in CP4D.
Environment
pipeline_custom
Input params
model_name, Select model_name from Train the Model node
deployment_name, Select deployment_name from Train the Model node
cloud_api_key, Select from pipeline parameter
model_id, Select model_id from Train the Model node
project_id, Select project_id from Train the Model node
space_id, String
Output params
deployment_status, Bool
deployment_id, String
model_id, String
space_id, String
This block is followed by a deployed? condition:

It runs the notebook monitor_models.ipynb:
This notebook source code can be found in monitor_models.ipynb, which does the following:
- Create subscription for the model deployment in Openscale
- Enable quality, fairness, drift, explainability, and MRM in Openscale
- Evaluate the model in Openscale
The trained model is saved to the model registry.
After the pipeline and model prediction service is verified to be successful in the pre-prod space, We can mannually deploy the model to the production environment.
This node has:
Environment
openscale
Input params
data_mart_id, String
model_name, Select model_name from Train the Model node
deployment_name, Select deployment_name from Train the Model node
cloud_api_key, Select from pipeline parameter
deployment_id, Select deployment_id from Deploy Model - Preprod node
model_id, Select model_id from Deploy Model - Preprod node
space_id, Select space_id from Deploy Model - Preprod node
service_provider_id, String
training_data_reference_file, String
Output params
None
Once the model is validated, and approved by the model validator, the model can be deployed to the prod environment.
In this example we reuse the deploy_model.ipynb and monitor_models.ipynb to create the deployment job.

This step checks if the the model is approved for production in Openscale.
It runs the notebook [Checks for Model Production.ipynb](Checks for Model Production.ipynb)
In this step, the validated model from the pre-prod is deployed in the production deployment space.
It runs the notebook deploy_model.ipynb
The input parameter space_id is the prod deployment space ID.
It runs the notebook monitor_models.ipynb
The Openscale API does not allow test data upload for Production subscriptions (like you'd upload for Pre-Production subscriptions). Therefore we save the data into Payload Logging and Feedback tables in Openscale and trigger on-demand runs for Fairness, Quality, Drift monitors and MRM.
Model retraining is governed by the underlying usecase.Following list is by no means exhaustive. Some of the common retraining methods are:
- Event based : When a business defined event occurs which explicitly impacts the objective of the model, a retrainig is triggered.
- Schedule based : Some of the models always rely on latest data viz: forecasting models. So such kind of retraining is schedule driven.
- Metric based : When a defined metric like model quality, bias or even data drift falls below a threshold , a retraining is triggered.
We have implemented the 3rd type of retraining as we are monitoring the data drift and augmenting the training data with the drifted records.
In OpenScale, the flow of the retraining looks like:
- Openscale model monitoring alerts are triggered, and an email is received: manually trigger the retrain job to update the data and restart the pre-prod pipeline
- Openscale model monitoring alerts are triggered, and an email is received: after some investigation, you decide that you want to try different models or features, therefore restart from the offline modeling stage.
In this project we also demonstrate how we put the model into the a model registry and track the model with AI Factsheets
You can instantiate a Factsheets (as shown in the train_models notebook) with
facts_client = AIGovFactsClient(api_key=apikey, experiment_name="CreditRiskModel", container_type="project", container_id=project_id, set_as_current_experiment=True)
and log the models in Factsheets with the save_log_facts() function in the notebook
After the model has been deployed to pre-prod and prod environments, and evaluated by Openscale, the deployments can be seen in the model entry (in Watson Knowledge Catalog):

.