issue with containers communicating with each other on same host #6
Comments
|
I have narrowed this down to the fact that the container stack does not respond to arp requests. ARP seems to be disabled on the IPVLAN interface in the container. This cannot be an issue with the IPVLAN kernel driver as it works correctly in the name space example I posted. There is something with docker and IPVLAN that is not setup correctly. |
|
after disabling arp on the interface in the namespace by issuing "ifconfig ipvl0 -arp" I was able to reproduce this issue in name space too. So docker seems to be disabling arp on the eth0 (IPVLAN) interface assigned to the container. I would like to know how to make docker not disable arp. |
|
Hey @shmurthy62 ! Sorry for the delay, I will dig into it tonight. I remember seeing that issue also with L2 mode. Im wondering if its a hairpin issue or how the iface is setup. Thanks a bunch for verifying it should work with iproute2 commands. Thats awesome! |
|
It's definitely an ARP issue. BTW I could not get L3 mode to work at all. I will first make it work with iproute2 and then debug the issue with ipvlanplugin driver. Important thing is to understand if docker shuts off arp on the interface. So far I have scanned through libnetwork code and I have not come across code that turns off arp so far. May be I missed something. |
|
Hi shmurthy62, I am a huge fan of L3 mode because it doesn't need any responders for ARP. I was scratching my head at first w/ L3 mode because I wasn't able to ping the ipvlan interface from the master interface (eth) and had them on the same subnet, different subnet, etc. I finally poked thru the netlink patch and saw everything from the head end of the interface pair (default ns eth0 for example) is filtered. So the cool thing is the underlying host is isolated from the namespace iface IP which makes sense for providers wanting a transparent underlying infra. So by design a namespace shouldn't be able to talk to the default namespace IP and ARP/Multicast is also filtered out. The trick with IPVlan is you need a route to the namespace that the IPVlan tail is attached to from the default namespace that ingress traffic would come into the master interface. Those should be separate subnets between default namespace and container namespace, thus L3 mode. The plugin should include that route, but since it is single host it will not add the route to other namespaces on other hosts. Something would need to distribute that. Could be a k/v store or any other distribution mechanism. I played around with using Git since there is an interesting logging/accounting property to bootstrapping or for example something I am very interested in using a routing protocol to distribute route/nexthop since those are well known and understood with to massive scale. Here is an example nerdalert/bgp-ipvlan-docker of distributing the routes if interested. /32 routes with BGP + IPVlan is probably the cleanest and least amount of things that can break with no ARP and a solid BGP FSM for packet forwarding. Lemme know if you get stuck and I will gist the output to be clearer on the routes for multihost. |
|
Hi Brent, Thanks for looking in to this for me. From what you are telling me L2 mode is not usable at all. How do you explain what I did with iproute2 and namespaces. In that case ARP is enabled on the interface in the name space with IPVLAN l2 mode. Is the GO netlink library disabling this. The L2 mode is quite simple if ARP is enabled. If we could optionally get (ip link set ${interface name} arp on) supported in the netlink package - we can set this up through the ipvlan plugin driver. If I understand you correctly L3 mode will require a BGP instance on each host - very similar to Calico solution. I will follow your suggestion and pursue L3. If we have to run BGP instance on each host and if the number of nodes is in 1000's it would be a nightmare to manage BGP and triage issues. In any case I will test this out. |
|
Hey shmurthy62, L2 should be usable, sorry was just talking about L3. I went to test it and ran into the latest GetCapabilities patch PR #516. Opened issue #7 to fix it. So I can't test it atm but will tomorrow. On the IPVlan there shouldn't be any filtering above netlink so Im betting its just something setup wrong in the L2 mode here. L3 mode would just require something to distribute network route and nexthop. L2 mode does this discovery with flooding and learning of mac addresses, L3 mode cares not for ethernet addresses since that is hidden away and the namespace is an altogether separate subnet from the default namespace. So distributing those routes would have to occur in some form or fashion, whether its etcd, bgp, zookeeper etc. If the environment is completely static then just declare it one time, burn it into the infra pointers and forget it but that takes a good crystal ball lol. Good point on the clustering node count btw lol. In that case is a completely declarative model of a /23 or something per host that is static and routed out of a ToR make more sense? Or alternatively munging network state into orchestration clustering for packet forwarding? Something about keeping network state separate feels right to me. Will update soon as I get issue #7 patched and verify L2 mode buddy. Thanks again for the help in getting this proofed out! |
|
@shmurthy62 I updated with the libnetwork API changes and verified L2 ipvlan mode. Pasting in a screenshot that shows two containers on the same docker host pinging one another. Lemme know if that doesn't work in your environment and I will try and replicate. I tested on two different hosts so it seems g2g. Cheers. |
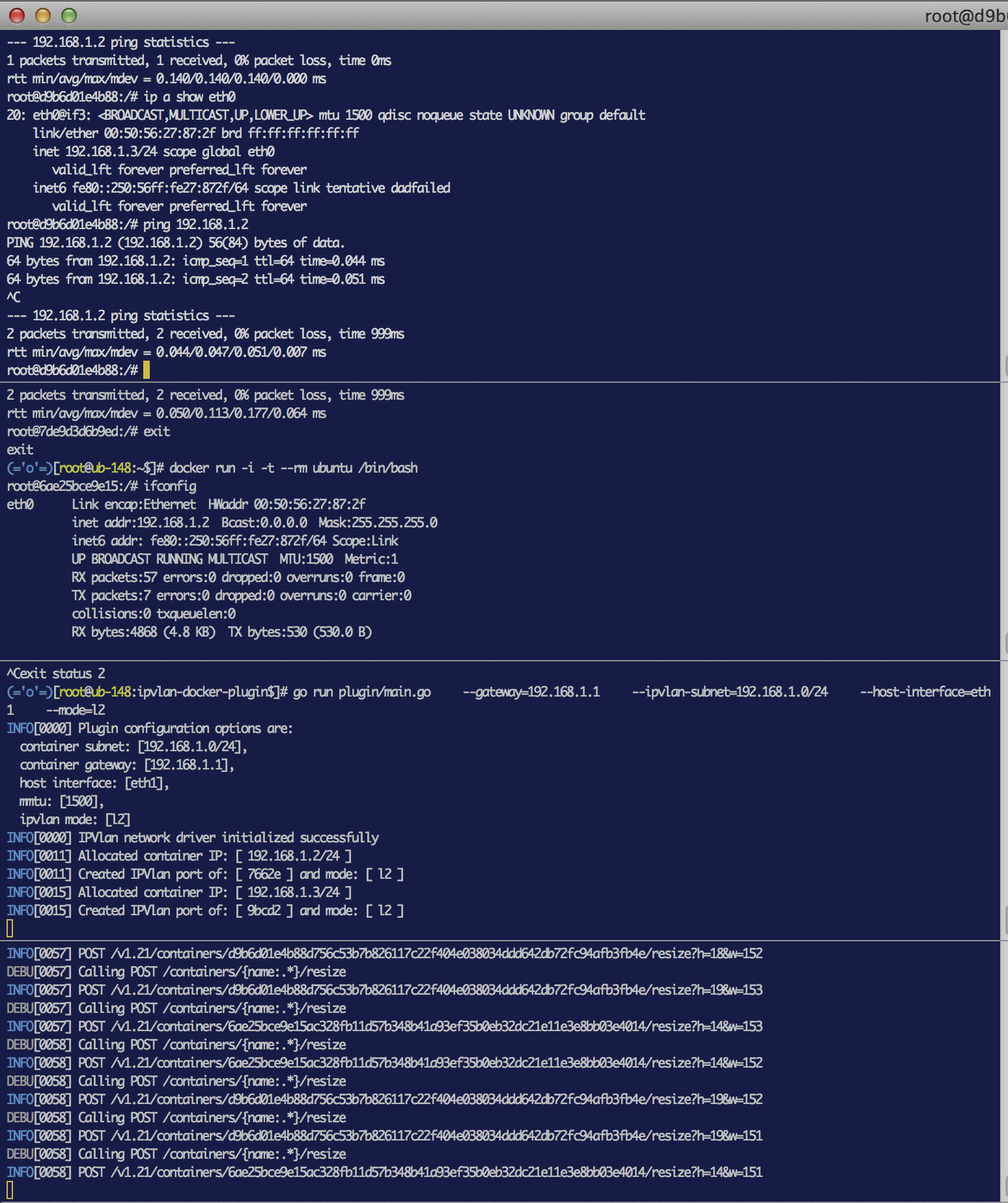
|
Does not work for me - I am trying to ping container on same host. ubuntu@ubuntu-1:~$ sudo docker run -i -t --rm ubuntu /bin/bash lo Link encap:Local Loopback root@027397c45225:/# ping 172.200.0.2 // pinging another docker container on same host ^C Now I ping my gw and can reach it root@027397c45225:/# ping 172.200.0.1 Now going across the router to remote host - no issues root@027397c45225:/# ping 172.201.0.101 remote host to this container - works because I pinged this host from container ubuntu@ubuntu-3:~$ ping 172.200.0.3 However if I ping the other container which is on same host as container 172.200.0.3 it does not work because of arp not responding. ubuntu@ubuntu-3:~$ ping 172.200.0.2 Not sure what is the issue - the ifconfig eth0 in the docker container shows arp is enabled but still it does if I ping remote host 172.201.0.101 from container 172.0.0.2 then the router learns its mac - after that I can ping from either end. Not sure why it works for you and not me. I only have trouble with docker container and not with iproute2 and namespaces I am using Ubuntu 14.04 and have deployed linux kernel 4.2 ubuntu@ubuntu-3:~$ uname -a can you tell me your version. Did something get fixed in netlink library in the last 2-3 weeks. My code ipvlan driver plugin code is that old. |
|
Hey! Thanks for the info, super helpful. I think I had mentioned I had run into something similar and I was able to reproduce it. Definitely agree you are following the exactly right thing with checking with iproute commands like you did. Your logs sure do look like a hairpin issue on the localhost. Have you setup macvlan links on the host at all recently? Ive noticed that if a macvlan link is defined pointing to the same master interface as an ipvlan interface it won't create a link. Thats not relevant to your situation since the interface was created but I figured I would throw it out there. Try this if you don't mind: Check Also might be worth checking syslogs and kernel msgs in case a clue is there if up to it: Btw, what is the container output for I put in the world's longest error message but it can really be a pita because all netlink says is the resource is busy. My host is just a bit newer but I was using the same kernel as you until y-day: Apprec the digging in, we will get support upstream packaged natively relatively soon but getting the early issues knocked out is going to be helpful so thanks again. If still hitting issues we can irc it out Monday too if up for it realtime. Lastly I updated and versioned the repo with new API updates that will work with the latest docker experimental in case you update one, just update the other. |
|
HI Brent, really appreciate you spending so much time with me. I did try out macvlan plugin driver before this on the same host - that worked great! I upgraded kernel to 3.19 first and then 4.2 to test IPVLAN. I rebooted the node before I started IPVLAN test and have rebooted the node several times after that. /var/run/docker/netns/ is clean. As far as my interface em1 going to promiscuous mode its because of running tcpdump atleast in my case. Here's the routes in one of my container root@18d9dd6a1343:/# ip route routes in another container root@eca6f0e96791:/# ip route BTW the interesting thing is if I ping a namespace (setup outside of docker) from within any of these containers I get a response mainly because the namespace ipvlan interface responds to arp request. // Here if you notice no arp reply for container to container pings // now when I ping a namespace @ 172.200.0.77 // now when I ping a namespace @ 172.200.0.39 Thanks again for your help. Sharad |
|
Hey Sharad, its my pleasure and very helpful so its me that owes you the thanks. The routes look spot on. I was feeling your pain so installed a 14.10 VM and the one thing I ran into of significance was the Docker experimental version. The Unfortunately none of that clues me into the issue you are having. What getting the latest experimental fixed was provisioning the link with the latest libnetwork API changes. Good thing is this is going to motivate me to get a Vagrantfile together to share with you. I will work on it tomorrow evening and Im guilty of never actually doing one cause it seems every project I ever work on @dave-tucker always did the vagrantfile lol. So hopefully tomorrow'ish I will push one. Thanks again buddy and check out the docker version for 14.10 in the readme updates if you have a second tomorrow. |
|
Hi Brent, I have some good news. I cleaned out /var/lib/docker/ from my nodes and after that everything works in l2 mode. I saw a few files under /var/lib/docker/containers/ hanging around from before. What exactly goes into this folder? I will continue testing to make sure there are no false positives. However I see one more thing which has to do with stability. Once the libnetwork driver hits an issue like I give it a wrong subnet and it reports an error like network not found, I see that I have to restart docker also along with the plugin driver. I can create a separate issue for this if you like. In the mean time I will start evaluating l3 mode. Did you by any chance try to setup an arp proxy on the host? |
|
Hi Brent, I now have the latest ipvlan driver code deployed. L2 checked out fine with this code. However L3 does not work at all. This is a docker issue. L3 mode works fine with Linux name spaces and hence not a driver issue. BTW I have BGP installed on all hosts now to create a L3 mesh. Here are the logs from docker and ipvlan driver WARN[0000] Running experimental build INFO[0006] Loading containers: done. ipvlan driver logs DEBU[0000] The plugin absolute path and handle is [ /run/docker/plugins/ipvlan.sock ] FYI I am running Linux L6430-1 4.2.1-040201-generic #201509211431 SMP Mon Sep 21 18:34:44 UTC 2015 x86_64 x86_64 x86_64 GNU/Linux one of the things missing in this kernel version is aufs module - I still went ahead with testing - don't see issues in L2 mode. I know docker needs it but for now I need to get libnetwork working. I cannot understand why docker is trying to set gateway for L3 mode. FYI in a namespace I add a default route as follows "ip route add 0.0.0.0/0 dev eth0". I only need this to get going. When I add the ip address for the ipvlan interface, I don't provide a mask with the address like in L2 mode and things work perfectly. Can you please look into this. Sharad |
|
Hey @shmurthy62 ! Apologies for the delay. Last week was crazy and have been working on a native driver for ipvlan/macvlan. Thanks in part to your great feedback I think we have enough of a PoC with the caveats to pursue pushing it upstream. The IPAM APIs are changing in experimental this week as it comes out of experimental, along with some minor others so I had to get that all rectified. I will ping you with the local branch I will probably just push here so we can collaborate with everyone easier as soon as Madhu's docker integration branch gets pushed into docker/docker feedback on the UX and functionality if you are up to it. Thanks for the help on getting this proofed out Sharad! |
|
Hi Brent, I hope by "native driver" you mean it will not require external libnetwork driver plugin as it is today - we would prefer this model. The current model is too brittle and has reliability issues. After my experience with current network plugin architecture we are not comfortable with the solution and are looking at using docker with --net=none option and implementing our own solution which I am against. This would be an interim solve till we get something concrete from docker. However I would strongly recommend revisiting the current network plugin model - the plugin should not impact the operation of of docker and vice versa. I would be happy to test out your native driver and provide feedback. I am looking for a functionality where we want to call a pre-processor in the name space before our application is executed in the docker container. Something like this ip netns exec preProcessor So 2 images need to be fetched one after another and executed in the same order specified within the container. Alternatively docker would take a fully qualified path to an application through a command line option and execute it in namespace before executing application. We want to hide this from the application developer who would write the docker file. Is there a way to achieve this today? Once I start testing I would recommend we move the conversation to irc or skype so its more realtime. |
|
Hey @shmurthy62 ! Having an in-tree driver is the goal. This was to shake out any early blockers which you have been super helpful with. The v1.9 API changes are merged for the most part so they will solidify. The API that is now out of experimental will leverage the Define a network and run some containers: Networks associated to different drivers simultaneously. I agree the hard part of having an external driver are the failure scenarios and float in state. Having the generic port creations upstream will take care of the single host operations. From there we can plug in whatever we want externally for state distribution. Something like IPVlan L3 mode doesn't really have a single host implementation since it requires routes to be added to other nodes needing to reach the subnet residing only in the namespace. It could be Etcd, Consul, whatever someone wants if they prefer a distributed datastore approach, or another one I am excited about is the GoBGP implementation that could propagate host routes or a summary for a pod etc. Will likely do the L3 mode experimentation here if there aren't any objections since the ipvlan functionality will be out of the box without a remote driver. The generic L2 use cases are super simple which is very attractive and something as simple as a ToR could route the L2 network getting plumbed up from a phy eth iface or a (m)LAG bonding. Will catch up with you, curious what your thoughts on L3 state distribution is too. The OSRG folks are super guys and I have been a fan of creating a Quagga replacement :) |
|
Thanks for considering making ipvlan a native driver. I would recommend sourcing config from a file - default could be /etc/docker/docker.conf. CLI options could override that. In production environment file is preferable. Re l2 mode: I agree L2 is super simple and will definitely work for us. It however will not allow IP mobility as the IP addresses will have to fall in the host's subnet. Re l3 mode: The beauty of this solve is it gives IP mobility. For us IP mobility is a want not a must. I have setup a BGP mesh using quagga in our lab. My current setup bypasses docker networking but I still use dockers. I think all docker needs to do is to setup a default route 0.0.0.0/0 via the ipvlan interface. Then ask IPAM for an IP address. Leave it to IPAM to figure out what IP address to dole out. In this mode the containers can have IP addresses outside the host subnet. This will provide IP mobility. I have a BGP instance per host peering with a BGP RR (Quagga Route server is even better). The BGP RR is at the leaf and will peer with a BGP at the spine level. In my current lab setup I am actually assigning a subnet to each host for docker containers and advertising it through BGP. However what I want to test is to inject a route per container IP (/32 address) in to the linux kernel and let BGP advertise it. I picked Quagga mainly because I can make it accept routes from the kernel and advertise it. I do not know how to do this with GoBGP (let me know if you know how to do it). Ideally docker should insert and remove the routes from the kernel based on the container lifecycle. If you can do that you leave it to the system integrator then to figure out how to advertise that route. I am currently prototyping this experience and will provide feedback once my thoughts are more concrete. L3 is a very complex setup and I want to make sure all failure modes are covered. I would want you to consider providing a REST API to expose config, state and stats. This way controllers can expose this to an operator. This will be very useful in large setups. |
|
Brent, if the content of the join response is : The daemon takes additional liberties if you just return: in which case it creates a bridged interface anyway on the default docker network ... I would be interested to understand the future of the plugin model, and how to make this work. |
|
I found the origin of the problem and filed moby/libnetwork#775 |
|
@jc-m @nerdalert Can you please help me, I am not sure what am I missing. Step 2 - Create Docker network: DEBU[0015] Network Create Called: [ {NetworkID:5a6c6ff0a97e9cf712165a6670445b55995c232e7528e521ae0a2f44f3ebaf48 Options:map[com.docker.network.generic:map[com.docker.network.driver.disable_default_gateway: host_iface:enp0s3 mode:l3]] IpV4Data:[{AddressSpace: Pool:192.169.57.0/24 Gateway:192.169.57.1/24 AuxAddresses:map[]}] ipV6Data:[]} ] Step 3: Start the contaiener, this is where it fails - Thanks |
|
Hey @shmurthy62 @jc-m ! Wanted to send this PR to you guys since you have been so helpful and patient on ipvlan issues. We are close to getting it into libnetwork natively. There is a link in the PR notes if you want to download the binary or compile it and give it a go. Thanks again, will be happy to get this in natively and then we can start doing fun state distribution and services! Thanks again for your input! |
I have experimental docker (Version : 1.9.0-dev) installed and I deployed ip-vlan-docker-plugin driver on my host after building it myself.
I start my driver as follows
./main --gateway=172.200.0.1 --ipvlan-subnet=172.200.0.0/22 --host-interface=em1 --mode=l2
it starts up fine. Then I launch 2 containers on this host both running busybox. It starts up fine and gets IP addresses assigned and I can see the routes are added to the route table in the container. I am pasting the output of "route -n" below from one of the containers. Both look same.
route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 172.200.0.1 0.0.0.0 UG 0 0 0 eth0
172.200.0.0 0.0.0.0 255.255.252.0 U 0 0 0 eth0
What I am finding is that I am unable to ping one container from the other container on the same host. However if I start another container on a remote host in another subnet, I am able to reach it without any issues. I know from a container I cannot reach host interface. However I expected that containers within the same host should be able to communicate with each other.
I decided to test this outside the docker ecosystem as follows
// create first name space and provision it
ip netns add ns0
ip link add link em1 ipvl0 type ipvlan mode l2
ip link set dev ipvl0 netns ns0
ip netns exec ns0 bash
ip link set dev ipvl0 up
ip -4 addr add 172.200.0.24/22 dev ipvl0
ip -4 route add default via 172.200.0.1 dev ipvl0
root@ubuntu:~# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 172.200.0.1 0.0.0.0 UG 0 0 0 ipvl0
172.200.0.0 0.0.0.0 255.255.252.0 U 0 0 0 ipvl0
// create a second name space
ip netns add ns1
ip link add link em1 ipvl1 type ipvlan mode l2
ip link set dev ipvl1 netns ns1
ip netns exec ns1 bash
ip link set dev ipvl1 up
ip -4 addr add 172.200.0.35/22 dev ipvl1
ip -4 route add default via 172.200.0.1 dev ipvl1
Both these namespaces are on the same host and I have no problem pinging the interfaces in each of these namespaces from the bash shell in the other namespace.
Problem seems to be with only the docker container. Has anybody else experienced similar problems?
The text was updated successfully, but these errors were encountered: